
Заполнение сзв м: Инструкция по заполнению отчета СЗВ-М в 2021 году
Заполнить сведения о застрахованных лицах
Заполнить сведения о застрахованных лицахВсе организации и индивидуальные предприниматели должны сдавать отчетность в Пенсионный фонд по форме «СЗВ-М». Если численность сотрудников более 25 человек, отчет представляется только в электронном виде.
Срок сдачи
Сведения подаются ежемесячно не позднее 15 числа месяца, следующего за отчетным периодом.
Ответственность за несданную отчетность
Как сформировать
- В разделе «Отчетность/Пенсионный» или «Учет/Отчетность/Пенсионный» (в зависимости от конфигурации) создайте отчет «СЗВ-М Сведения о застрахованных лицах».
- Проверьте, правильно ли указан получатель и реквизиты организации.
- Перейдите в раздел «Сотрудники», нажмите «+ Сотрудник» и добавьте работников.
- Заполните СНИЛС и ИНН сотрудников.
Как заполнить
Подробнее о формулах расчета и содержании каждого раздела читайте здесь.
Как отправить
Проверьте и отправьте отчет. Он считается принятым, когда Пенсионный фонд пришлет положительный протокол.
Он считается принятым, когда Пенсионный фонд пришлет положительный протокол.
- В разделе «ПФР» создайте новый отчет и выберите форму «СЗВ-М Сведения о застрахованных лицах».
- Проверьте отчетный период, представителя в ПФР и нажмите «Далее».
- На вкладке «Отредактировать отчет» нажмите «Сведения о застрахованных лицах».
- В открывшемся окне кликните «Добавить» и выберите сотрудников.
- Проверьте СНИЛС и ИНН работников. Если они не указаны, выделите строку с ФИО сотрудника, нажмите «Изменить» и заполните сведения.
Как заполнить
Подробнее о формулах расчета и содержании каждого раздела читайте здесь.
Также вы можете посмотреть встроенную справку по заполнению.
Как отправить
Проверьте и отправьте отчет. Он считается принятым, когда Пенсионный фонд пришлет положительный протокол.
- В разделе «Пенсионный» создайте отчет и выберите форму «СЗВ-М Сведения о застрахованных лицах».
- Нажмите «Сведения о застрахованных лицах».

- В открывшемся окне кликните «Добавить» и выберите сотрудников.
- Убедитесь, что у каждого работника указаны СНИЛС и ИНН работников. Если нет, откройте сведения о сотруднике и заполните их.
- В разделе «Реквизиты» проверьте данные организации, получателя и подписанта.
Как заполнить
Подробнее о формулах расчета и содержании каждого раздела читайте здесь.
Также вы можете посмотреть встроенную справку по заполнению.
Как отправить
Проверьте и отправьте отчет. Он считается принятым, когда Пенсионный фонд пришлет положительный протокол.
Нашли неточность? Выделите текст с ошибкой и нажмите ctrl + enter или свяжитесь с нами.
СЗВ-М: если нет начислений, как заполнить СЗВ-М, если нет начислений
Сведения о застрахованных лицах по форме СЗВ-М обязаны представлять ежемесячно не позднее 15 числа все страхователи, у которых в отчетном месяце действовали, заключались, или расторгались трудовые и гражданско-правовые договоры, облагаемые «пенсионными» взносами. Это все еще относительно новый для нас отчет – появился СЗВ-М в 2016 г.
Это все еще относительно новый для нас отчет – появился СЗВ-М в 2016 г.
Если нет начислений работникам по причине приостановки деятельности предприятия, нахождения работников в неоплачиваемом отпуске и т.п. – это не является основанием для несдачи сведений в Пенсионный фонд. Каковы особенности заполнения СЗВ-М в таком случае, рассмотрим далее.
Как заполнить СЗВ-М, если нет начислений
В форме СЗВ-М (утв. постановлением Правления ПФР от 01.02.2016 № 83п) отражаются следующие сведения о работниках: Ф.И.О., страховой номер ПФР (СНИЛС), ИНН (при наличии данных). Производились ли в отчетном месяце начисления, или нет, не имеет значения – форма не содержит денежных показателей о доходе и начисленных «пенсионных» взносах.
Сведения СЗВ-М, если нет начислений, подаются на всех сотрудников, с которыми в отчетном месяце действовали трудовые и облагаемые ГПХ-договоры (письмо ПФР от 27.07.2016 № ЛЧ-08-19/10581). В сведениях нужно отражать и тех, кто находится в отпуске без содержания, сотрудниц в декретном отпуске и отпуске по уходу за ребенком.
Какие нюансы следует учитывать
Договор, действующий даже 1 день в отчетном месяце, должен быть отражен в СЗВ-М. Такая ситуация может сложиться, например, когда работник уволился в первый день месяца, или был принят на работу последним числом отчетного месяца.
Если какие-то суммы были начислены работнику позднее месяца его увольнения, отражать его в сведениях не нужно. Например: работник уволился и получил расчет в феврале. В апреле, обнаружив ошибку в расчете, ему доначислили и выплатили некоторую сумму. Данные по работнику будут включены в сведения за февраль, а в апреле его отражать не надо, несмотря на наличие начислений, ведь договор с ним уже не действовал.
Как заполнить СЗВ-М, если нет начислений при полной остановке хоздеятельности фирмы и отсутствии работников? В такой ситуации сведения о застрахованных лицах подаются только на руководителя организации, если действует заключенный с ним договор. Во время процесса ликвидации предприятия сведения СЗВ-М подаются на ликвидатора.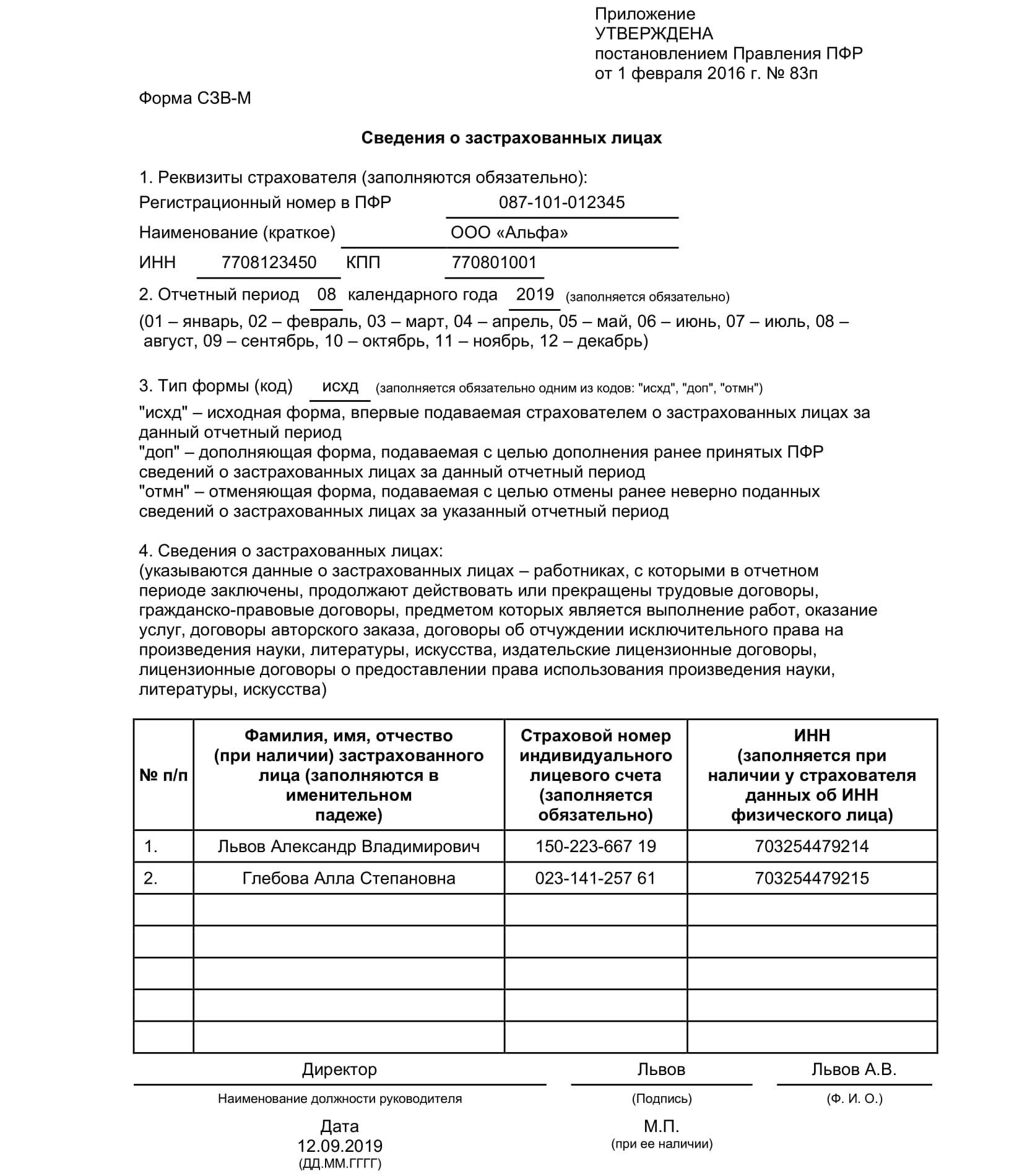
Как сдать отчет по форме СЗВ-М?
Получать статьи на почту
Подключите сервис 1С-Отчетность бесплатно на 30 дней!
Шаг 1. Открытие раздела Документы персучета
Рис. 1. Вкладка Отчетность, справки в 1С: ЗУП ред. 3.1
Шаг 2. Создание отчета по форме СЗВ-М
В отрывшемся разделе Документы персучета нажимаем на кнопку Создать и выбираем Сведения о застрахованных лицах, СЗВ-М.
Рис. 2. Раздел Документы персучета
Шаг 3.
 Заполнение отчета по форме СЗВ-М
Заполнение отчета по форме СЗВ-МВ отчете выбираем отчетный период и тип формы «Исходная». Нажимаем кнопку Заполнить.
Рис. 3. Заполнение отчета о застрахованных лицах
Шаг 4. Проверка корректности заполнения отчета
Сервис позволяет запустить программу, проверяющую корректность заполнения отчета.
На кнопке Отправить нажмите на стрелку вниз и выберите Проверить в Интернете.
Рис. 4. Проверка корректности заполнения отчета
В открывшемся окне заполните согласие на передачу персональных данных и нажмите Продолжить.
Рис. 5. Форма согласия на передачу персональных данных
По итогам проверки отчета программа выдаст сообщение. Если ошибок в отчете не обнаружено, переходите к следующему шагу.
Рис.![]() 6. Сообщение об отсутствии ошибок в отчете
6. Сообщение об отсутствии ошибок в отчете
Шаг 5. Отправка отчета в Пенсионный фонд РФ
На кнопке Отправить нажмите на стрелку вниз и выберите Отправить в ПФР.
Рис. 7. Отправка отчета в ПФР
Подтвердите, что отчет заполнен полностью и корректно, нажмите отправить.
Рис. 8. Подтверждение отправки отчета
Далее вы увидите сообщение о том, что отчет успешно отправлен в ПФР.
Рис. 9. Сообщение о сдаче отчета
Шаг 6. Проверка отправки отчета
Для того чтобы проверить отправку отчета в разделе Отчетность, справки, зайдите в раздел 1С-Отчетность.
Рис. 10. Вкладка Отчетность, справки в 1С: ЗУП ред. 3.1
В разделе Отчеты можно увидеть отправленные в контролирующие органы документы и их статус. Отчет по форме СЗВ-М сразу после отправки будет иметь статус Отправлено в ПФР.
Отчет по форме СЗВ-М сразу после отправки будет иметь статус Отправлено в ПФР.
Рис. 11. Вкладка Отчеты в разделе 1С-Отчетность
После обновления информации с контролирующими органами статус отчета должен измениться на Отчет успешно сдан.
С сервисом 1С-Отчетность сдать отчет просто и удобно. Вы можете оформить у нас бесплатный доступ на месяц к сервису, для того чтобы попробовать в работе все преимущества.
Подключите сервис бесплатно на 30 дней!
Ответы на часто возникающие вопросы
Когда сдавать отчет
Отчет о застрахованных лицах необходимо сдавать до 15-го числа месяца, следующего за отчетным.
Кому нужно сдавать отчет
Всем организациям и ИП, имеющим в найме сотрудников по трудовому и гражданско-правовому договору, необходимо подавать в ПФР сведения о застрахованных лицах.
В отчет должны включаться сотрудники в декрете, отпуске и уволившиеся в рамках отчетного периода.
Можно ли сдавать отчет досрочно
Отчет можно сдать с 1-го числа месяца, следующего за отчетным.
Как исправить ошибку в отчете
Чтобы исправить ошибку в сведениях отчета по форме СЗВ-М, необходимо заполнить и отправить дополняющую/отменяющую форму.
Остались вопросы?
Наши специалисты свяжутся с вами, чтобы уточнить подробности!
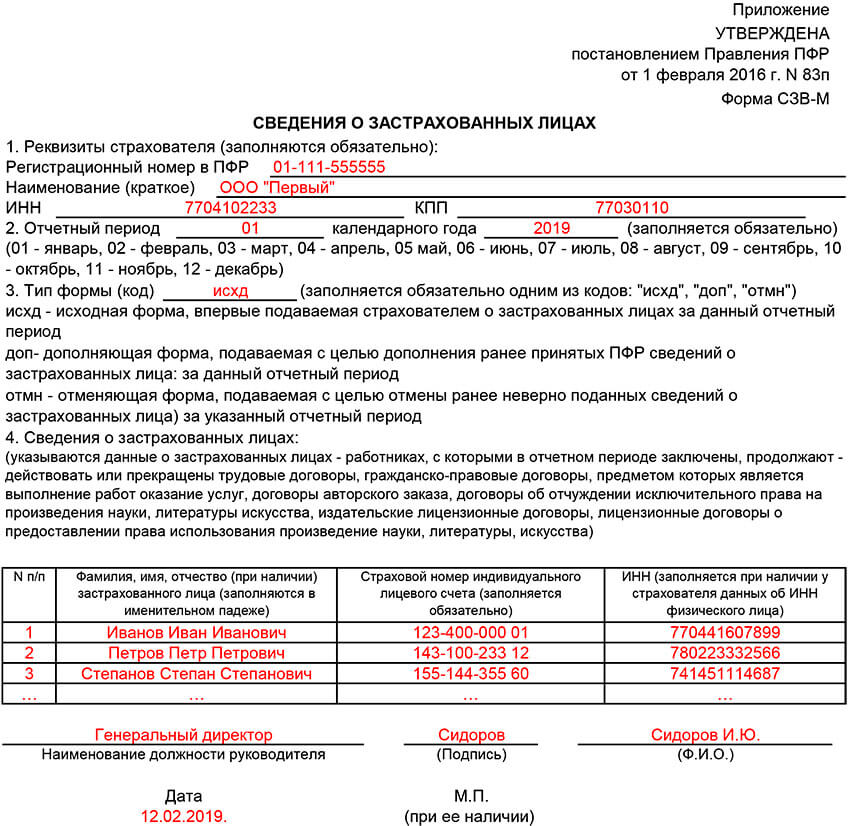
Как заполнить СЗВ-М: порядок и образец заполнения
С апреля 2016 года работодатели, которые заключили трудовые договора со своими сотрудниками, обязаны подавать ежемесячную форму отчетности в Пенсионный фонд СЗВ-М. Необходимо знать, как правильно заполнять такой документ и образец его заполнения.
Особенности заполнения формы СЗВ-М ПФР
В самом начале необходимо разобраться, что представляет собою данная форма.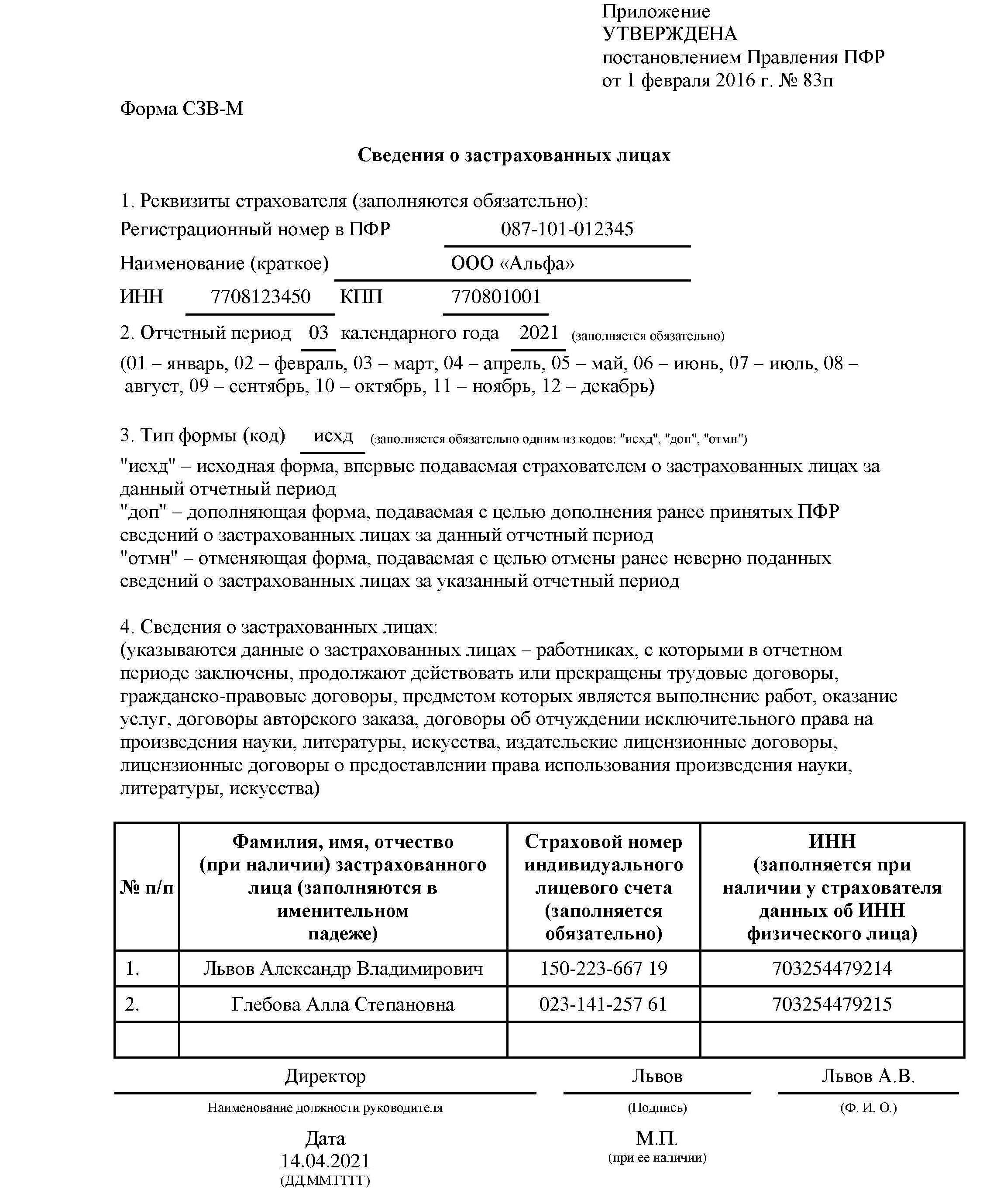
СЗВ-М ПФР– это сведения о застрахованных, входящие, то есть информация, которая поступает в Пенсионный фонд обо всех работающих по договорам людях. Буква М говорит о том, что подавать такую информацию нужно раз в месяц.
Все сведения вносятся абсолютно на каждого работника, даже на тех, кто находится в отпуске или декрете. Пенсионеры тоже входят в этот список. Главным условием считается наличие трудового договора. Это значит, что работник получает заработную плату, которая облагается страховыми взносами в Пенсионный фонд РФ.
Сдавать форму СЗВ-М можно двумя способами:
- на бумажном носителе – только для тех организаций и предпринимателей, у которых численность работников не превышает 25 человек. Тогда ее можно сдать лично или прислать почтой;
- в электронном виде – тут надо не забыть добавить электронно-цифровую подпись.
Важно понимать, что при несвоевременной подаче отчетности или сдаче с недостоверными сведениями или ошибками, сотрудники Пенсионного фонда наложат штраф на организацию.
Инструкция по заполнению
Заполняется такая форма отчетности обычно сотрудником бухгалтерии. Но с такой задачей легко справится и работник отдела кадров, потому как у обоих имеется вся необходимая информация на каждого сотрудника. Решение о том, кто будет ответственным за заполнение отчета, принимает руководитель организации.
Получите 267 видеоуроков по 1С бесплатно:
Подается СЗВ-М ежемесячно до 15 числа месяца, который следует за отчетным. Тогда, когда крайний срок сдачи выпадает на праздничный или выходной день, он переносится на ближайший рабочий.
Необходимо точно знать, как правильно заполняется форма СЗВ-М. Инструкция по заполнению СЗВ-М на бумажном носителе выглядит приблизительно так:
Раздел 1 содержит реквизиты страхователя. Тут указываются:
- регистрационный номер, который присваивается организации или предпринимателю, присылается почтой в уведомлении. Узнать его можно в Пенсионном фонде или налоговой службе;
- краткое наименование компании или индивидуального предпринимателя;
- вписывается ИНН и КПП предпринимателя и организации.

Раздел 2 содержит информацию об отчетном периоде с указанием месяца и года.
Раздел 3 включает сведения о форме подаваемой отчетности из предложенных вариантов. Обязательно необходимо выбрать один из них:
- исхд – исходная, которая подается первый раз;
- доп – дополняющая, которая содержит дополнительную информацию, не указанную ранее. Старые сведения сюда уже не вписываются;
- отмн – отменяющая, которая полностью отменяет все указанные ранее данные.
Раздел 4 содержит всю информацию о застрахованных лицах, которые работают по трудовому договору:
- полностью фамилия, имя, отчество;
- СНИЛС физического лица;
- ИНН – если работодатель не владеет информацией о нем, то его можно уточнить у застрахованного лица или узнать на сайте ФНС.
Не имеет значения, в какой последовательности указывать работников, можно в алфавитном порядке или в любом другом. В самом конце документа ставится должность руководителя, его подпись и печать организации.
СЗВ-М: образец заполнения
Каждому заполняющему форму СЗВ-М нужно перед глазами иметь образец. Тогда не возникнет никаких проблем и ошибок:
Нулевой отчет сдавать не нужно, если нет соответствующих договорных отношений, если нет работников или не ведется никакая трудовая и хозяйственная деятельность. Также отчетность в Пенсионный фонд не будет сдавать индивидуальный предприниматель, у которого отсутствуют работники.
Как заполнить СЗВ-М онлайн
Заполнять такой вид отчетности можно онлайн, это намного быстрее и легче. Разработано несколько сервисов, позволяющих заполнить форму СЗВ-М:
- бухсофт;
- СКБ Контур;
- контур-отчет ПФ.
Первым из них является сайт Бухсофт. Благодаря нему получится заполнить форму, сформировать полный пакет документов, проверить все ошибки, распечатать бумагу, направить отчет по защищенным каналам связи.
Все пункты, кроме последнего производятся бесплатно. Необходимо зарегистрироваться на сайте, что не займет много времени. После чего надо заполнить форму:
После чего надо заполнить форму:
- заходим в личный кабинет и вписываем все свои реквизиты;
- после чего на главной странице надо выбрать вкладку онлайн-сервисы и нажать на кнопку СЗВ-М;
- потом нажимаем подготовить отчет;
- указываем всю информацию на своих работников;
- нажимаем формирование — готовые отчеты и кнопку формировать;
- проводим проверку на ошибки;
- печатаем файл, если надо сохраняем на компьютере.
Эти действия не займут много времени.
Второй сервис работает с организациями и предпринимателями в специальных режимах и бесплатен в течение месяца. Тут надо выполнить следующие действия:
- зарегистрироваться на сайте;
- заполнить в личном кабинете все реквизиты организации;
- на главной странице ищем отчетность и выбираем форму СЗВ-М за нужный период;
- вписываем информацию о работниках;
- проводим проверку;
- кнопка — другие способы сдать отчет;
- распечатываем файл, сохранив его на компьютере.

Третий сервис дает возможность работать бесплатно полгода. Весь алгоритм действий такой же точно, как и в двух других. Тут существует возможность задать вопрос менеджеру сайта онлайн.
Заполнение формы отчетности онлайн в Пенсионный фонд возможно разными способами, что является очень удобным аспектом. Самое главное, подавать СЗВ-М вовремя, тогда не возникнет никаких проблем с фондом.
Заполнение СЗВ-М при отпуске работника за свой счет
Вопрос от 10.04.2017
У меня вопрос по новой форме отчета в налоговую, а именно Расчет по страховым взносам. В моей компании работает два человека. При этом один из них получает зп, налоги платим.
Второй сотрудник отправлен в административный отпуск без сохранения зп. У меня программа автоматически в разделе 1. прил.1 и разделе 1. прил. 2 (количество застрахованных лиц) ставит 2 (человека). При этом в разделе 1. прил. 1 строка 020 (кол-во физ. лиц, с выплат которым начислены страховые взносы), ставит 1 (человек, как и должно быть). А в разделе 3 заполняется форма только по работающему и получающему зарплату сотруднику. Мне все оставить как есть? Боюсь, что будут расхождения с СЗВ-М, т.к. в отчете указываю двоих. Или, возможно, добавить в раздел 3 второго сотрудника, только с нулевыми начислениями?
А в разделе 3 заполняется форма только по работающему и получающему зарплату сотруднику. Мне все оставить как есть? Боюсь, что будут расхождения с СЗВ-М, т.к. в отчете указываю двоих. Или, возможно, добавить в раздел 3 второго сотрудника, только с нулевыми начислениями?
Ответ: Рекомендуем заполнить в разделе 3 «Расчета по страховым взносам» пункт 3.1 «Данные о физическом лице – получателе дохода» данные по сотруднику, находящемуся в «административном отпуске. А пункт 3.2 «Сведения о сумме выплат и иных вознаграждений, исчисленных в пользу физического лица, а также сведения о начисленных страховых взносах на обязательное пенсионное страхование» не заполнять (или заполнить с нулевыми значениями).
Обоснование:
В пункте 4 Формы отчетности «Сведения о застрахованных лицах» указываются сведения о застрахованных лицах – работниках, с которыми в отчетном периоде заключены, продолжают действовать или прекращены трудовые договоры, гражданско-правовые договоры. Согласно п. 2.2 ст. 11 Федерального закона от 01.04.1996 № 27-ФЗ “Об индивидуальном (персонифицированном) учете в системе обязательного пенсионного страхования» организация-страхователь ежемесячно представляет отчет о каждом работающем у него застрахованном лице. При этом на основании ст. 7 Федерального закона от 15.12.2001 № 167-ФЗ “Об обязательном пенсионном страховании в Российской Федерации” под работающими гражданами (застрахованными лицами) понимаются, в частности, лица, работающие по трудовому договору, но находящиеся в «Административном отпуске».
Согласно п. 2.2 ст. 11 Федерального закона от 01.04.1996 № 27-ФЗ “Об индивидуальном (персонифицированном) учете в системе обязательного пенсионного страхования» организация-страхователь ежемесячно представляет отчет о каждом работающем у него застрахованном лице. При этом на основании ст. 7 Федерального закона от 15.12.2001 № 167-ФЗ “Об обязательном пенсионном страховании в Российской Федерации” под работающими гражданами (застрахованными лицами) понимаются, в частности, лица, работающие по трудовому договору, но находящиеся в «Административном отпуске».
Таким образом, в отчете по форме СЗВ-М необходимо указывать сведения о работнике, с которым заключен трудовой договор, но который находится в «административным отпуске».
Обращаем Ваше внимание на Порядок заполнения формы «Расчет по страховым взносам» утверждённый Приказом ФНС России от 10 октября 2016 г. № ММВ-7-11/551@.
В главе 22 данного приказа, утвержден порядок заполнения раздела 3 “Персонифицированные сведения о застрахованных лицах” расчета.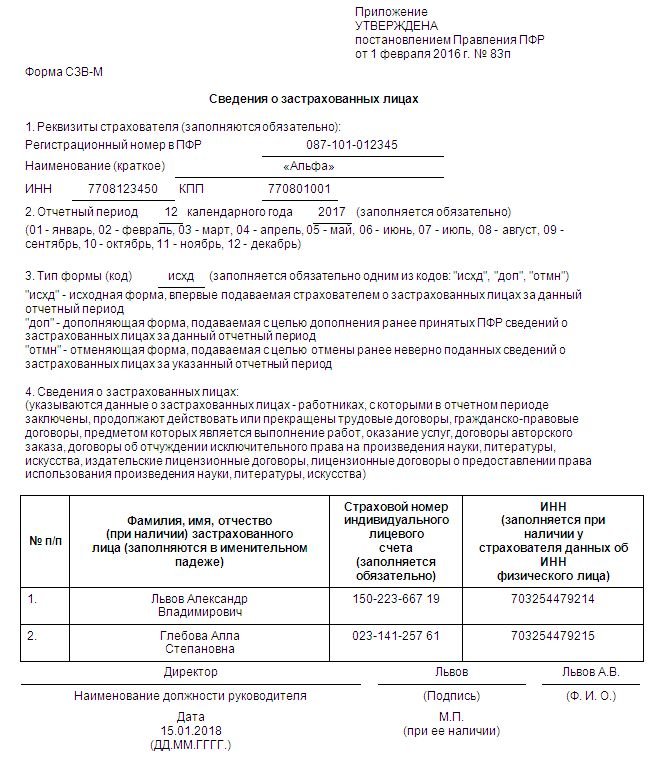 Согласно п. 22.1 в данный раздел расчета заполняется плательщиками на всех застрахованных лиц за последние три месяца расчетного (отчетного) периода, в том числе в пользу которых в отчетном периоде начислены выплаты и иные вознаграждения в рамках трудовых отношений и гражданско-правовых договоров, предметом которых является выполнение работ, оказание услуг, или с которым заключены трудовые договоры и (или) гражданско-правовые договоры.
Согласно п. 22.1 в данный раздел расчета заполняется плательщиками на всех застрахованных лиц за последние три месяца расчетного (отчетного) периода, в том числе в пользу которых в отчетном периоде начислены выплаты и иные вознаграждения в рамках трудовых отношений и гражданско-правовых договоров, предметом которых является выполнение работ, оказание услуг, или с которым заключены трудовые договоры и (или) гражданско-правовые договоры.
Отмечаем, что согласно п. 22.2 порядка заполнения, в персонифицированных сведениях о застрахованных лицах в которых отсутствуют данные о сумме выплат и иных вознаграждений, начисленных в пользу физического лица за последние три месяца отчетного (расчетного) периода, подраздел 3.2 раздела 3 не заполняется.
Таким образом, расхождения между сведениями о застрахованных лицах в СЗВ-М и разделе 3 Расчета по страховым взносам должны отсутствовать.
Как сформировать СЗВ М в 1С 8.3
Форма СЗВ-М – ежемесячная отчетность в Пенсионный Фонд, где отражаются сведения о застрахованных лицах. Если в течение месяца даже на один день с работником был заключен трудовой договор либо договор ГПХ, то значит, его необходимо включить в отчет и сдать в ПФР. В качестве наглядного пособия постараемся показать как сделать СЗВ-М в 1С 8.3 (8.2) ЗУП и Бухгалтерия 3.0.
Если в течение месяца даже на один день с работником был заключен трудовой договор либо договор ГПХ, то значит, его необходимо включить в отчет и сдать в ПФР. В качестве наглядного пособия постараемся показать как сделать СЗВ-М в 1С 8.3 (8.2) ЗУП и Бухгалтерия 3.0.
Цель отчета СЗВ-М, сроки, состав сведений и штрафы проиллюстрированы ниже:
Более подробно для чего заполняется форма СЗВ-М, особенности заполнения формы СЗВ-М читайте в нашей статье.
Где найти и как сформировать СЗВ М в 1С 8.3
В 1С 8.3 Бухгалтерия 3.0 СЗВ-М можно получить из формы 1С-Отчетность либо заполнить СЗВ-М из раздела «Зарплата и кадры» – «ПФР, Пачки, реестры, описи»:
Далее «Создать» – «Сведения о застрахованных лицах, СЗВ-М»:
При нажатии Заполнить в 1С 8.3 автоматически формируются данные, при этом необходимо обязательно проверить заполнение графы СНИЛС.
Если в базе 1С 8.3 не заполнен СНИЛС, то этот сотрудник не попадет в сведения о застрахованных лицах по форме СЗВ-М. Поэтому нужно взять за правило, что при приеме на работу либо при заключении договора ГПХ, сразу запросить у сотрудника СНИЛС и ввести его в базу 1С 8.3 не дожидаясь конца месяца. В противном случае отчетность СЗВ-М по этому сотруднику не сможете сдать. ИНН указывается при наличии:
Поэтому нужно взять за правило, что при приеме на работу либо при заключении договора ГПХ, сразу запросить у сотрудника СНИЛС и ввести его в базу 1С 8.3 не дожидаясь конца месяца. В противном случае отчетность СЗВ-М по этому сотруднику не сможете сдать. ИНН указывается при наличии:
Как заполнить СЗВ М в 1С ЗУП 2.5 (8.2)
В программе 1С 8.2 ЗУП 2.5 есть закладка «ПФР» – «Сведения о застрахованных лицах, СЗВ-М»:
Создаем новый отчет, который автоматически заполняется по кнопке Заполнить:
Заполнение СЗВ М в 1С ЗУП 8.3
В 1С 8.3 ЗУП выбираем «Отчетность, справки» – «ПФР, Пачки, реестры, описи»:
По кнопке «Создать» выбираем «Сведения о застрахованных лицах, СЗВ-М»:
Далее нажать кнопку «Заполнить»:
Если организация только перешла на работу в программе 1С 8.3 (8.2) и впервые собирается формировать форму СЗВ-М, то нужно учесть, что в Пенсионный фонд предоставляется файл в формате XML. Имя этого файла формируется по определенным правилам. Одним из составляющих имени, является код территориального органа ПФР.
Программа 1С 8.3 (8.2) «берет» код органа ПФР из настроек организации, из закладки Фонд, где должен быть указан код территориального органа ПФР. Обычно это первые шесть символов из регистрационного номера. Соответственно, если этот код не задан в базе 1С 8.3 (8.2), то имя файла формируется неверно:
В настоящее время в программах 1С встроена проверка, поэтому при выгрузке файла программа 1С подскажет, что не заполнены поля и необходимо ввести код органа ПФР:
При этом необходимо дозаполнить данные и повторить выгрузку. Тогда файл будет выгружен правильно. После чего можно отправлять в Пенсионный фонд.
Особенности заполнения СЗВ-М
Например, сотрудница поменяла фамилию и обратилась самостоятельно в фонд для замены страхового свидетельства, при этом работодателя об этом не известила.
В этом случае ПФ изменит фамилию в страховом свидетельстве и в своей базе. И если работодатель сдаст отчетность со «старой» фамилией сотрудницы, то Пенсионный фонд пришлет запрос дополнительных сведений, так как номер СНИЛС не соответствует фамилии.
Поэтому необходимо подать сведения по этой сотруднице повторно. При этом если работодатель успевает в срок подать повторные сведения, то тогда обойдется без штрафов. Но если не успеет в установленный срок, то ПФР имеет право оштрафовать. В связи с этим, рекомендуется подавать форму СЗВ-М заранее, чтобы было время исправить неточности в сведениях о сотрудниках.
Например, сотрудник не выходит на работу, отражаются прогулы и начисления зарплаты нет.
В этом случае нужно указывать сотрудника в форме СЗВ-М. Даже если сотрудник не работал целый месяц и его не уволили за прогулы, но при этом имеется трудовой договор, то по нему необходимо подать сведения.
Например, компания только зарегистрировалась и функция генерального директора у единственного учредителя – физического лица, при этом заработная плата не начислялась и не выдавалась.
В этом случае нужно обратиться в свой Пенсионный фонд и узнать информацию о предоставлении отчета СЗВ-М в данной ситуации.
Поскольку в ПФР данные в СЗВ–М будут сопоставляться с данными по форме РСВ-1, и если в РСВ-1 единственный директор-учредитель не будет указан, а в СЗВ-М будет отражен, то возникнет «нестыковка» данных. Поэтому рекомендация только одна – обратиться в Пенсионный фонд и узнать, как они хотят получить информацию.
Поставьте вашу оценку этой статье: Загрузка…
Дата публикации: Июл 11, 2016
Поставьте вашу оценку этой статье:
Загрузка…Форма СЗВ-М для ежемесячной отчетности в ПФР
Выбрать журналАктуальные вопросы бухгалтерского учета и налогообложенияАктуальные вопросы бухгалтерского учета и налогообложения: учет в сельском хозяйствеБухгалтер Крыма: учет в унитарных предприятияхБухгалтер Крыма: учет в сельском хозяйствеБухгалтер КрымаАптека: бухгалтерский учет и налогообложениеЖилищно-коммунальное хозяйство: бухгалтерский учет и налогообложениеНалог на прибыльНДС: проблемы и решенияОплата труда: бухгалтерский учет и налогообложениеСтроительство: акты и комментарии для бухгалтераСтроительство: бухгалтерский учет и налогообложениеТуристические и гостиничные услуги: бухгалтерский учет и налогообложениеУпрощенная система налогообложения: бухгалтерский учет и налогообложениеУслуги связи: бухгалтерский учет и налогообложениеОплата труда в государственном (муниципальном) учреждении: бухгалтерский учет и налогообложениеАвтономные учреждения: акты и комментарии для бухгалтераАвтономные учреждения: бухгалтерский учет и налогообложениеБюджетные организации: акты и комментарии для бухгалтераБюджетные организации: бухгалтерский учет и налогообложениеКазенные учреждения: акты и комментарии для бухгалтераКазенные учреждения: бухгалтерский учет и налогообложениеОплата труда в государственном (муниципальном) учреждении: акты и комментарии для бухгалтераОтдел кадров государственного (муниципального) учрежденияРазъяснения органов исполнительной власти по ведению финансово-хозяйственной деятельности в бюджетной сфереРевизии и проверки финансово-хозяйственной деятельности государственных (муниципальных) учрежденийРуководитель автономного учрежденияРуководитель бюджетной организацииСиловые министерства и ведомства: бухгалтерский учет и налогообложениеУчреждения здравоохранения: бухгалтерский учет и налогообложениеУчреждения культуры и искусства: бухгалтерский учет и налогообложениеУчреждения образования: бухгалтерский учет и налогообложениеУчреждения физической культуры и спорта: бухгалтерский учет и налогообложение
20192020
НомерЛюбой
Электронная версия
Изучите SVM 101 за 5 минут. Мотивация | by Haitian Wei
На долгое время я застрял в странной петле: я изучал алгоритмы и много времени тратил на детали моделей. Я был уверен, что понял модель. И через месяц-два я практически все забыл о модели. И я еще раз пересмотрел модель и снова забыл.
Эта ситуация вызывает наибольшее разочарование, когда вы приходите на собеседование. Поэтому я решил остановиться и пересмотреть свое учебное поведение. Что не так? Как разорвать эту петлю? Потом кое-что произошло.Это способ рисования наброска, который дает мне подсказку.
Итак, чтобы закончить хороший набросок, вы сначала прорабатываете контур , а затем постепенно заполняете детали , такие как тени, текстуры и так далее. То же самое и с изучением модели.
Очертания модели – это ключевая интуиция, лежащая в основе модели, ее плюсов и минусов. То, как работает математика, и ее пошаговые выводы – вот в чем дело. Если контур шаткий, детали долго не продержатся.
Функция ошибки
SVM пытается найти гиперплоскость, которая наилучшим образом разделяет разные классы обучающих данных. Среди множества гиперплоскостей с ошибкой классификации SVM найдите гиперплоскость с максимальным запасом, то есть точки данных находятся дальше всего от гиперплоскости.
Источник: UdacityТаким образом, функция ошибок SVM – это ошибка классификации плюс погрешность запаса. А параметр C контролирует, насколько мы заботимся об ошибке классификации.
Ошибка классификации SVM вычисляется, как показано ниже, обратите внимание, что точки данных, попадающие в граничную область, также обрабатываются как ошибка.Суммарное расстояние точек ошибки до плоскости разделения является ошибкой классификации.
Источник: UdacityИ такая функция потерь называется потеря петли .
Мы можем увидеть, чем она отличается от других функций потерь на рисунке ниже. Зеленая линия обозначает потерю шарнира.
Источник: https://scikit-learn.org/stable/auto_examples/linear_model/plot_sgd_loss_functions.htmlОшибка поля помогает нам найти лучший самолет среди множества самолетов с такой же ошибкой классификации.Это также можно рассматривать как штраф за регуляризацию .
Запас определяется как расстояние между разделяющей гиперплоскостью (границей решения) и обучающими выборками, ближайшими к этой гиперплоскости, которые являются так называемыми опорными векторами . Это показано на следующем рисунке:
Большой запас означает, что граница принятия решения имеет хорошую способность к обобщению и не будет влиять на небольшие изменения данных.
Другой способ интерпретации погрешности запаса – рассматривать ее как штраф за регуляризацию.Норма веса два означает, что мы предпочитаем меньшие веса, чем большие веса.
Таким образом, ошибка классификации (потеря шарнира) и погрешность запаса вместе дают окончательную функцию ошибки SVM.
Уловка с ядром
Другой аспект импорта SVM – уловка с ядром. Что, если точки данных не могут разделиться линейно? Мы можем поднять точки в более высокие измерения с помощью ядра, а затем разделить данные с помощью гиперплоскости!
Ниже представлена хорошая визуализация того, как работает полиномиальное ядро .
И есть много функций ядра на выбор, некоторые общие функции ядра показаны на рисунке ниже.
Для получения более подробной информации о методах ядра, таких как воспроизведение гильбертова пространства ядра (RKHS) и теоремы Мерсера, есть хорошая вводная статья.
Сильные стороны модели
Это надежная модель, потому что это регуляризованный метод. Параметры C контролируют штраф за ошибки. Для больших значений C оптимизация выберет гиперплоскость с меньшим запасом, если эта гиперплоскость лучше справляется с получением всех тренировочных точек, классифицированных правильно.
Уловка с ядром – настоящая сильная сторона SVM. С помощью трюка с ядром SVM может решить любые нелинейные границы принятия решений.
SVM определяется задачей выпуклой оптимизации (без локальных минимумов), для которой существуют эффективные методы (например, SMO)
Недостатки модели
SVM требует большого объема памяти, поскольку вам необходимо хранить матрицу ядра NxN, которая может быть очень большой если N большое O (t2).
SVM занимает много времени, когда набор данных большой O (t3).
SVM трудно реализовать на множественной классификации.Если вы настаиваете на использовании SVM для решения нескольких задач классификации, обычно существует два способа: «один стих один» и метод «один стих много».
Общим недостатком непараметрических методов, таких как SVM, является отсутствие прозрачности результатов . SVM не может представить результат как простую параметрическую функцию входных данных, поскольку его размер может быть очень высоким. Это не линейная комбинация входов и не другая простая функциональная форма.
Существует множество приложений SVM, например Практическое промышленное приложение SVM для диагностики механических неисправностей , Категоризация текста с помощью машин опорных векторов: обучение с множеством соответствующих функций .
https://www.quora.com/Why-are-SVMs-memory-intensive
https://www.quora.com/What-is-the-computational-complexity-of-an-SVM
Сравнение методов заполнения пробелов, применяемых в базе данных CCI о влажности почвы в Южной Европе
Влажность почвы (SM) – ключевая переменная, которая играет важную роль во взаимодействиях суша-атмосфера. Мониторинг SM имеет решающее значение для многих приложений и может помочь определить влияние изменения климата. Следовательно, очень важно иметь непрерывные и долгосрочные базы данных для этой переменной.Этому способствовали спутниковые миссии; однако непрерывность ряда нарушена из-за пробелов в данных, полученных из-за различных факторов, включая время повторного посещения, наличие сезонного льда или загрязнение радиочастотными помехами (RFI). В этой работе применимость различных методов заполнения пробелов оценивается на комбинированном продукте SM Инициативы по изменению климата (CCI) ESA, который является самой длинной доступной записью спутниковых данных SM. Использовались методы линейной, кубической и авторегрессионной интерполяции и опорные векторные машины (SVM).Это исследование было сосредоточено на Южной Европе и охватывало период 2003–2015 годов. Различные методы применялись во временной и пространственной областях и оценивались с использованием метода перекрестной проверки удержания. Набор переменных был введен в модель SVM для оценки SM, а именно, температура поверхности земли, осадки, нормализованный разностный индекс растительности (NDVI), потенциальное испарение, текстура почвы и географические координаты. Для SVM было рассмотрено несколько комбинаций этих переменных, включая анализ главных компонентов (PCA), содержащий все из них.Хотя разные методы в целом показывают хорошую производительность, метод SVM превосходит остальные. Использование SM предыдущего дня (SM t-1 ) является ключом к получению хороших оценок. Среднее значение коэффициента корреляции (R), полученное с помощью SVM и серии SM t-1 при временном анализе, составило 0,83, а RMSE – 0,025 м 3 м −3 . Аналогичные результаты были получены при пространственном анализе с лучшими характеристиками ( R = 0,88; RMSE = 0.024 м 3 м −3 ), полученные SVM с использованием серии SM t-1 и статических переменных. Применение PCA к входным переменным не принесло пользы, а методы интерполяции потерпели неудачу при работе с большими пространственными или временными промежутками. Также была проведена валидация серии CCI SM с данными in situ SM из четырех сетей, расположенных в Испании, Франции, Германии и Италии, и не было обнаружено существенных различий между результатами, полученными с исходной серией и с реконструированной серией.Кроме того, лучшие входные данные, полученные с помощью SVM, были использованы для оценки метода случайного леса (RF) во временной и пространственной областях. Этот метод показал хорошую способность оценивать значения влажности почвы во временной области, но в меньшей степени, чем SVM, в то время как для пространственной области он не казался таким точным. Наши результаты подтверждают, что мы можем эффективно справляться с пространственно-временными пробелами в базах данных наблюдательных СМ, используя метод SVM и прошлые временные ряды и текстуру почвы в качестве вспомогательной информации.
Система поддержки принятия решений на основе машины опорных векторов для диагностики заболеваний пародонта | Примечания к исследованию BMC
Методы
В этом поперечном исследовании были изучены записи 300 пациентов, направленных в отделение пародонтологии Университета медицинских наук Хамадан, к западу от Ирана, в период с сентября 2016 года по июнь 2018 года. На основании консультации с двумя опытными специалистами в области пародонтологии, а также обзора клинических исследований были выбраны желаемые переменные [14, 15, 21, 23].Соответствующие значения выбранных переменных были извлечены и записаны для каждого пациента с соблюдением принципов полной конфиденциальности. Это исследование было одобрено Комитетом по этике исследований Университета медицинских наук Хамадан с IR.UMSHA.REC.1398.154.
Машина опорных векторов
SVM – это один из контролируемых методов обучения, используемых для классификации и регрессии. SVM основан на теории статистического обучения. SVM – это алгоритм, который находит определенный тип линейной модели, которая максимизирует запас гиперплоскостей.Максимальное увеличение запаса гиперплоскостей приведет к максимальному разделению между классами. Ближайшие точки обучения к максимальному запасу облачности – это опорные векторы. Только эти векторы (точки) используются для задания границы между классами (рис. 1). Предполагая, что категории являются линейно разделяемыми, он получает гиперплоскости с максимальным запасом для разделения категорий. Задача поиска оптимальной линии для данных решается методами QP, которые являются хорошо известными методами решения задач с ограничениями [16].
Рис. 1Машина опорных векторов для данных, разделяемых по линейности
В задачах, где данные не разделимы линейно, с помощью функции ядра данные отображаются в пространство большего размера, чтобы их можно было линейно разделить в этом новом пространстве . В этой ситуации могут использоваться различные ядерные функции, такие как линейные, радиальные, полиномы и сигмоид [17].
Оценка производительности модели
Перекрестная проверка – это метод оценки того, как результаты модели прогнозирования, такой как SVM, будут обобщены на независимый набор данных.Цель перекрестной проверки – проверить способность модели предсказывать новые данные, которые не использовались при ее построении.
Один раунд перекрестной проверки включает в себя случайное разбиение всех данных на k подмножеств (сверток), затем построение прогнозной модели на основе одного подмножества (называемого обучающим набором) и оценку эффективности прогнозирования на основе другого подмножества (так называемая проверка набор или набор для тестирования). Этот процесс повторяется до тех пор, пока каждая K-кратность не станет тестовым набором. Наконец, зарегистрированные меры точности объединены (средние) для получения более точной оценки характеристик прогнозирования модели [4].
Кроме того, мы пробуем гиперобъем под ROC-многообразием (HUM) в качестве альтернативной меры погрешности для оценки модели SVM. В отличие от общей меры точности правильной классификации, HUM не зависит от распространенности класса и, таким образом, отражает внутреннюю точность классификатора [18].
Следует также отметить, что в текущем исследовании диагноз профессионала рассматривается как золотой стандарт для оценки прогностической эффективности модели.
Построение модели классификации SVM
В модели классификации SVM переменные, включая возраст (продолжение), пол (мужской, женский), курение (да, нет), потерю привязанности (продолжение), индекс налета (процент), пакет зондирования глубина (продолжение), десневой индекс (степень I, степень II, степень III, степень IV), потеря альвеолярной кости (оценка: 0 для ABL ≤ 20%, 1 для 20 ≤ ABL ≤ 50%, 2 для ABL ≥ 50% на основе на рентгенографии), индекс кровотечения из сосочков (0, 1, 2, 3), подвижность (нет, да) и упрощенный индекс гигиены полости рта (0, 1, 2, 3), используемые в качестве входных данных, и индивидуальный статус заболевания пародонта в качестве выходных данных. переменная состоит из трех классов (гингивит, локализованный пародонтит, генерализованный пародонтит).Также оцениваются различные функции ядра, такие как линейное ядро, многочлен, сигмоид и радиальный. Для оценки производительности модели SVM использовался критерий точности и конфигурация матрицы неточностей.
Все анализы были выполнены с использованием «caret», «HUM» и «mcca» – свободно доступного пакета из Comprehensive R (R3.6.3) Archive Network (CRAN).
Результаты
В таблице 1 сравниваются средние значения непрерывных переменных, связанных с потерей прикрепления, индексом налета, глубиной зондирующего кармана и возрастом в трех группах.Результаты показали, что средняя разница потери прикрепления, индекса зубного налета, переменных глубины зондирования кармана в трех группах была значительной, но средний возраст не был значимым в трех группах. В таблице 1 также показано частотное распределение переменных, таких как пол, курение, индекс десен, индекс кровотечения из сосочков, потеря альвеолярной кости и здоровье полости рта по группам. Результаты показывают, что группы не различаются по половому признаку. Между тремя группами была значительная разница по всем переменным.В таблице 2 представлено сравнение производительности различных моделей SVM, основанных на различных функциях ядра, с точки зрения индекса точности и значений HUM на основе десятикратной перекрестной проверки. Результаты показывают, что модель классификации SVM, основанная на функции радиального ядра, имеет лучшую производительность с общей точностью правильной классификации 88,7% с использованием десятикратного метода перекрестной проверки. Кроме того, правильная классификация гингивита по категориям составила 96,0%, а для локализованного пародонтита – 64.0%, а при генерализованном пародонтите 92,2%. Дальнейшая оценка модели SVM с использованием критериев HUM показала, что общее значение HUM было равно 0,912.
Таблица 1 Сравнение различных переменных между тремя классами болезней (Хамадан на западе Ирана – сентябрь 2016 г. – июнь 2018 г.) Таблица 2 Сравнение производительности различных функций ядра (десятикратная перекрестная проверка)Обсуждение
В В этом исследовании для классификации пациентов с пародонтитом использовался метод классификации SVM.Результаты настоящего исследования показывают, что разработанная классификационная модель имеет приемлемую эффективность в прогнозировании периодонтита. Использование точной модели для прогнозирования заболеваний пародонта может быть полезно стоматологам с небольшим опытом. На самом деле использование таких систем может привести к снижению страха (из-за отсутствия знаний, навыков, одиночества) и повышению самооценки, особенно у молодых врачей. Развитие и развитие этих систем может обеспечить удовлетворение заинтересованных сторон систем здравоохранения, и также возможно, что при разработке и использовании систем принятия решений в портативных устройствах помощника врача или медицинских компьютерах в медицинских кабинетах, предоставляющих медицинские инструменты в реальном времени для практикующие врачи для постановки более надежных диагнозов [19, 20].
Несколько исследований подтвердили, что распространенность и тяжесть заболеваний пародонта увеличиваются с возрастом [21]. Аналогичный результат наблюдался в настоящем исследовании, хотя не было статистически значимой разницы в среднем возрасте между различными классами заболевания, средний возраст пациентов увеличивался с увеличением тяжести заболевания.
Накапливаются данные о более высоком уровне заболеваний пародонта среди курильщиков [21]. В настоящем исследовании процент курильщиков увеличивался с увеличением тяжести заболевания.
Далее классификационная модель, представленная в этом исследовании, будет сравнена с некоторыми исследованиями, связанными с прогнозированием периодонтита.
Ozden et al. Провели исследование на 150 пациентах с пародонтом. В этом исследовании использовались три модели классификации, включая машину опорных векторов, дерево решений и нейронную сеть. Среди них машина опорных векторов и дерево решений имеют более высокую точность для классификации заболеваний пародонта с точностью 98%, а худшую производительность имеет ИНС с точностью 46% [22].
Youssif et al. Провели исследование с участием 30 пациентов на основании клинических данных, включая индекс зубного налета, глубину кармана и уровень клинического прикрепления, а также данные по гематоксилину и эозину, полученные от людей, которые были разделены на три диагностические группы: увеличение десен. , хронический пародонтит и хронический гингивит. Используемая статистическая модель – это ИНС прямого распространения и обратного распространения с рейтингом точности 100% [8].
Arbabi et al., Провели исследование в Иране. Они разделили 190 пациентов на две группы (n = 160 для поезда) и (n = 30 для теста) и изучили их, изучив в качестве входных переменных возраст, пол, индекс зубного налета, глубину кармана зондирования и индекс потери клинического прикрепления.В этой работе использовались два алгоритма Левенберга-Маркуардета (LM) и Scaled Conjugate Gradient (SCG), результаты показали, что LM обеспечивает лучшую производительность, чем SCG [23].
Папантонопулос и др. Использовали модель искусственной нейронной сети (ИНС) вместе с информацией о пациентах для классификации пациентов по двум категориям хронического пародонтита и агрессивного пародонтита. Точность ИНС для классификации данных составляла 90–98% [24].
На самом деле нет никаких биологических или вычислительных причин, по которым конкретный метод классификации лучше подходит для прогнозирования результата в различных условиях.В общем, невозможно найти метод, который всегда лучше всего подходит для классификации различных наборов данных. Следовательно, необходимы дополнительные исследования, чтобы найти лучший классификатор для каждого набора данных.
По нашему мнению, более точные результаты могут быть получены при добавлении в систему большего числа пациентов с различными типами стойких системных и пародонтальных проблем. Вероятно, что характеристики классификации могут быть улучшены с использованием некоторых других классификаторов, будущие исследования могут быть сосредоточены на другой модели классификации, такой как нечеткие экспертные системы.Будущие исследования могут быть выполнены для определения наиболее важных прогностических переменных, таких как воспалительные маркеры, системные факторы, стресс и уровень образования при классификации пародонтита.
Выводы
Система поддержки принятия решений, основанная на машине опорных векторов, оказалась очень точной для диагностики заболеваний пародонта. Разработка точных систем поддержки принятия решений облегчает и ускоряет диагностические процессы. Система, разработанная в этом исследовании, поможет менее опытным стоматологам и молодым резидентам принимать решения по диагностике заболеваний пародонта.
Прогнозирование потоков углерода и водяного пара с использованием машинного обучения и новых алгоритмов ранжирования характеристик
Данные о потоках, заполняющих пробелы, с использованием количественных подходов, увеличились за последнее десятилетие. Ранее было предложено множество методов, в том числе подходы с использованием таблиц поиска, параметрические методы, модели на основе процессов и машинное обучение. В частности, во многих исследованиях широко использовались пакет REddyProc от Института биогеохимии Макса Планка и пакет ONEFlux от AmeriFlux.Однако нет единого мнения относительно оптимальной модели и метода выбора характеристик, которые можно было бы использовать для прогнозирования различных целевых потоков (Net Ecosystem Exchange, NEE; или Evapotranspiration -ET), из-за ограниченного систематического сравнительного исследования, основанного на идентичных данных участка. . Здесь мы сравнили эффективность заполнения / прогнозирования NEE и ET для линейной модели на основе наименьших квадратов, искусственной нейронной сети, случайного леса (RF) и машины опорных векторов (SVM), используя данные, полученные от четырех основных пропашных культур и кормовые агроэкосистемы, расположенные в субтропической зоне или зоне с переходным климатом в США.Кроме того, мы протестировали влияние различных настроек разделения данных для обучения и тестирования, включая 10-кратную последовательную временную серию (10FTS), 10-кратную процедуру перекрестной проверки (CV) с одной точкой данных (10FCV), ежедневную (10FCVD). , еженедельный (10FCVW) и ежемесячный (10FCVM) интервал, а также подход с 7/14-дневным фланговым окном (FW); и реализовал новый алгоритм рекурсивного исключения признаков на основе фрагментированной обратной регрессии (SIRRFE). Мы сравнили производительность модели с результатами, полученными с помощью REddyProc и ONEFlux.Наши результаты показали, что точные модели прогнозирования NEE и ET могут быть систематически построены с использованием SVM / RF и только нескольких основных информативных функций. Эффективность заполнения зазоров ONEFlux в целом удовлетворительна (R 2 = 0,39-0,71), но результаты REddyProc могут быть очень ограниченными или даже ненадежными во многих случаях (R 2 = 0,01-0,67). В целом модели SVM, доработанные с помощью SIRRFE, дали отличные результаты для прогнозирования NEE (R 2 = 0,46-0,92) и ET (R 2 = 0.74-0,91). Наконец, на производительность различных моделей сильно влияли типы экосистем, прогнозируемые цели и алгоритмы обучения; но был нечувствителен к разделению на обучение и тестирование. Наши исследования позволили лучше понять построение новых моделей заполнения пробелов и понимание основных движущих сил, влияющих на потоки углерода / воды в пограничном слое на уровне экосистемы.
Ключевые слова: Ковариация вихрей; Рейтинг характеристик; Машинное обучение; Дистанционное зондирование; Машина опорных векторов.
Машинный классификатор опорных векторов– Amazon Macie Classic
Это руководство пользователя Amazon Macie Classic. Для получения информации о новый Amazon Macie, см. пользователя Amazon Macie Гид. Чтобы получить доступ к консоли Macie Classic, откройте консоль Macie по адресу https://console.aws.amazon.com/macie/, а затем выберите Macie Classic на панели навигации.
Другой метод, который Macie Classic использует для классификации ваших объектов S3, – это Support Векторная машина (SVM) классификатор. Он классифицирует контент внутри ваших объектов S3 (текст, n-граммы токенов, а также символьные n-граммы), которые отслеживает Macie Classic, и их функции метаданных (документ длина, extension, encoding, headers) для точной классификации документов на основе содержимого.Этот классификатор, управляемый Macie Classic, был обучен на большом корпусе обучения данные различных типов и оптимизирован для поддержки точного обнаружения различных типов контента, включая исходный код, журналы приложений, нормативные документы и резервные копии баз данных. В классификатор также может обобщать свои обнаружения.Например, если он обнаружил новый вид из исходный код, который не соответствует ни одному из типов исходного кода, которому он обучен к признать, он может обобщить обнаружение как «исходный код».
Этот метод классификации данных не отображается в настройках страница.Macie Classic управляет следующим списком артефактов. Вы не можете редактировать, включать, или отключить их.
Классификатор SVM в Macie Classic обучен обнаруживать следующие типы контента:
Электронные книги
Электронная почта
Общие ключи шифрования
Финансовый
JSON
Журналы AWS CloudTrail
Ноутбуки Jupyter
Журналы приложений
Формат Apache
Журналы сервера Amazon S3
Системный журнал Linux
База данных
Резервное копирование MongoDB
Резервное копирование MySQL
MySQL скрипт
Исходный код
F #
VimL
ActionScript
Сборка
Баш
Пакетный файл
С
Clojure
Кобол
CoffeeScript
CUDA
Эрланг
Фортран
Перейти
Haskell
Java
JavaScript
LISP
Lua
Матлаб
ObjectiveC
Perl
PHP
PowerShell
Обработка
Python
R
Рубин
Scala
Swift
VHDL
Веб-языки
SVM-SulfoSite: предсказатель на основе машины опорных векторов для сайтов сульфенилирования
Poole, L. B. & Schoneich, C. Введение: что мы знаем и чего не знаем о окислительно-восстановительных процессах тиолов в сигнальных путях. Free Radic Biol Med 80 , 145–147 (2015).
Артикул PubMed PubMed Central CAS Google Scholar
Роос, Г. и Мессенс, Дж. Образование белковой сульфеновой кислоты: от клеточного повреждения до окислительно-восстановительной регуляции. Free Radic Biol Med 51 , 314–326 (2011).
Артикул PubMed CAS Google Scholar
Чанг, Х.С., Ван, С.Б., Венкатраман, В., Мюррей, К.И. и Ван Эйк, Дж. Э. Окислительные посттрансляционные модификации цистеина: возникающая регуляция в сердечно-сосудистой системе. Circ Res 112 , 382–392 (2013).
Артикул PubMed PubMed Central CAS Google Scholar
Янг, Дж., Гупта, В., Кэрролл, К. С. и Либлер, Д. С. Сайт-специфическое картирование и количественная оценка S-сульфенилирования белка в клетках. Нац Коммуна 5 , 4776 (2014).
Артикул PubMed PubMed Central ОБЪЯВЛЕНИЯ CAS Google Scholar
Пул, Л. Б. Основы тиолов и цистеинов в окислительно-восстановительной биологии и химии. Free Radic Biol Med 80 , 148–157 (2015).
Артикул PubMed CAS Google Scholar
Леонард С. Э. и Кэрролл К. С. Химические «омические» подходы к пониманию окисления белков цистеина в биологии. Curr Opin Chem Biol 15 , 88–102 (2011).
Артикул PubMed CAS Google Scholar
Пул, Л. Б. и Нельсон, К. Дж. Обнаружение механизмов сигнального окисления цистеина. Curr Opin Chem Biol 12 , 18–24 (2008).
Артикул PubMed PubMed Central CAS Google Scholar
Вани Р. и др. . Изоформ-специфическая регуляция Akt с помощью PDGF-индуцированных активных форм кислорода. Proc Natl Acad Sci USA 108 , 10550–10555 (2011).
Артикул PubMed ОБЪЯВЛЕНИЯ Google Scholar
Линдаль М., Мата-Кабана А. и Кизельбах Т. Дисульфидный протеом и другие реактивные цистеиновые протеомы: анализ и функциональное значение. Антиоксид. Редокс. Сигнализация , 14 , 2581-2642 (2011).
Артикул CAS Google Scholar
Weerapana, E. и др. . Количественное определение профиля реактивности позволяет прогнозировать функциональные цистеины в протеомах. Природа 468 , 790–795 (2010).
Артикул PubMed PubMed Central ОБЪЯВЛЕНИЯ CAS Google Scholar
Wang, C., Weerapana, E., Blewett, M. M. & Cravatt, B. F. Хемопротеомная платформа для количественного картирования мишеней электрофилов, полученных из липидов. Nat Methods 11 , 79–85 (2014).
Артикул PubMed CAS Google Scholar
Szychowski, J. и др. . Расщепляемые биотиновые зонды для мечения биомолекул посредством азид-алкинового циклоприсоединения. J Am Chem Soc 132 , 18351–18360 (2010).
Артикул PubMed PubMed Central CAS Google Scholar
Чжэн Т., Цзян Х. и Ву П. Одноцепочечная ДНК как расщепляемый линкер для протеомики на основе биоортогональной химии. Bioconjug Chem 24 , 859–864 (2013).
Артикул PubMed PubMed Central CAS Google Scholar
Qian, Y. et al . Расщепляемый линкер на основе азобензола с изотопной меткой для количественной протеомики. Chembiochem 14 , 1410–1414 (2013).
Артикул PubMed CAS Google Scholar
Фурдуй, К. М. и Пул, Л. Б. Химические подходы к обнаружению и анализу белковых сульфеновых кислот. Mass Spectrom Rev 33 , 126–146 (2014).
Артикул PubMed ОБЪЯВЛЕНИЯ CAS Google Scholar
Qian, J. et al. . Простая и эффективная стратегия мечения цистеинсульфеновой кислоты в белках путем использования бета-кетоэфиров в качестве расщепляемых зондов. Chem Commun (Camb) 48 , 4091–4093 (2012).
Артикул CAS Google Scholar
Буй, В. М., Лу, К. Т., Хо, Т. Т. и Ли, Т. Ю. MDD-SOH: использование максимального разложения зависимости для идентификации сайтов S-сульфенилирования с субстратными мотивами. Биоинформатика 32 , 165–172 (2016).
PubMed CAS Google Scholar
Xu, Y., Ding, J. & Wu, L. Y. iSulf-Cys: Прогнозирование сайтов S-сульфенилирования в белках с физико-химическими свойствами аминокислот. PLoS One 11 , e0154237 (2016).
Артикул PubMed PubMed Central CAS Google Scholar
Буй, В. М. и др. . SOHSite: включает информацию об эволюции и физико-химические свойства для идентификации сайтов S-сульфенилирования белка. BMC Genomics 17 (Приложение 1), 9 (2016).
Артикул PubMed PubMed Central CAS Google Scholar
Сакка, М. и др. . ПРЕССА: Сервер PRotEin S-сульфенилирования. Биоинформатика 32 , 2710–2712 (2016).
Артикул PubMed CAS Google Scholar
Ван, X., Ян, Р., Ли, Дж. И Сонг, Дж. SOHPRED: новый инструмент биоинформатики для характеристики и прогнозирования сайтов S-сульфенилирования человека. Мол Биосист 12 , 2849–2858 (2016).
Артикул PubMed CAS Google Scholar
Lei, G. -C., Tang, J. & Du, P. -F. Прогнозирование сайтов S-сульфенилирования с использованием различий физико-химических свойств. Письма по органической химии 14 , 665–672 (2017).
Артикул CAS Google Scholar
Hasan, M. M., Guo, D. & Kurata, H. Вычислительная идентификация сайтов S-сульфенилирования белка путем включения информации о множественных характеристиках последовательностей. Мол Биосист 13 , 2545–2550 (2017).
Артикул PubMed CAS Google Scholar
Исмаил, Х. Д., Джонс, А., Ким, Дж. Х., Ньюман, Р. Х. и К. К., Д. Б. RF-Phos: новый инструмент для прогнозирования места общего фосфорилирования на основе случайного леса. Biomed Res Int 2016 , 3281590 (2016).
Артикул PubMed PubMed Central CAS Google Scholar
Исмаил, Х.Д., Ньюман, Р. Х. и К. К., Д. Б. RF-гидроксизит: предсказатель на основе случайного леса для сайтов гидроксилирования. Мол Биосист 12 , 2427–2435 (2016).
Артикул PubMed PubMed Central CAS Google Scholar
Хассан, Х., Бадр, А. и Абдельхалим, М. Б. Прогнозирование сайтов O-гликозилирования с использованием метода случайного леса и метода PSO с настройкой GA. Bioinform Biol Insights 9 , 103–109 (2015).
Артикул PubMed PubMed Central CAS Google Scholar
КришнаВени, К. и Собха Рани, Т. О классификации несбалансированных наборов данных. IJCST 2 , 145–148 (2011).
Google Scholar
Гуо, X., Инь, Й., Донг, К., Ян, Дж. И Чжоу, Г. О проблеме дисбаланса классов. в Natural Computing, 2008.ICNC’08. Четвертая Международная конференция по , Vol. 4 192–201 (IEEE, 2008).
Коциантис, С., Канеллопулос, Д. и Пинтелас, П. Обработка несбалансированных наборов данных: обзор. GESTS International Transactions on Computer Science and Engineering 30 , 25–36 (2006).
Google Scholar
Чжоу К. и Чжан К. Т. Прогнозирование структурных классов белков. Crit Rev Biochem Mol Biol 30 , 275–349 (1995).
Артикул PubMed CAS Google Scholar
Пан, З. и др. . Систематический анализ перекрестных помех in situ модификаций тирозина не обнаруживает дополнительного естественного отбора на множественно модифицированных остатках. Научный представитель 4 , 7331 (2014).
Артикул PubMed PubMed Central CAS Google Scholar
Xu, H. D., Shi, S. P., Wen, P. P. и Qiu, J. D. SuccFind: новый инструмент для онлайн-прогнозирования сайтов сукцинилирования с помощью стратегии улучшенных характеристик. Биоинформатика 31 , 3748–3750 (2015).
PubMed CAS Google Scholar
Лю Б. и др. . iDNA-Prot | dis: идентификация ДНК-связывающих белков путем включения пар аминокислотных расстояний и сокращенного алфавитного профиля в общий псевдоаминокислотный состав. PLoS One 9 , e106691 (2014).
Артикул PubMed PubMed Central ОБЪЯВЛЕНИЯ CAS Google Scholar
Boughorbel, S., Jarray, F. & El-Anbari, M. Оптимальный классификатор для несбалансированных данных с использованием показателя «Коэффициент корреляции Мэтьюза». PLoS One 12 , e0177678 (2017).
Артикул PubMed PubMed Central CAS Google Scholar
Пауэрс, Д. М. У. Оценка: от точности, отзыва и F-меры к ROC, информированности, заметности и корреляции. J. Mach. Учить. Technol. 2, 37–63 (2011).
Ши, С. П., Чен, Х., Сюй, Х. Д. и Цю, Дж. Д. PredHydroxy: расчетное предсказание местоположения сайтов гидроксилирования белка на основе первичной структуры. Мол Биосист 11 , 819–825 (2015).
Артикул PubMed CAS Google Scholar
Кавашима, С. и др. . AAindex: база данных аминокислотных индексов, отчет о ходе работы за 2008 г. Nucleic Acids Res 36 , D202–205 (2008).
Артикул PubMed CAS Google Scholar
Чжао, X. и др. . Позиционно-зависимый анализ и прогнозирование сайтов пупилирования белков на основе множества характеристик. Biomed Res Int 2013 , 109549 (2013).
PubMed PubMed Central Google Scholar
Чжэн, Л. Л. и др. . Прогнозирование сайтов модификации белков пирролидонкарбоновой кислоты с использованием выбора и анализа характеристик mRMR. PLoS One 6 , e28221 (2011).
Артикул PubMed PubMed Central ОБЪЯВЛЕНИЯ CAS Google Scholar
Xu, Y., Ding, Y. X., Ding, J., Wu, L. Y. & Xue, Y. Mal-Lys: прогнозирование сайтов малонилирования лизина в белках, интегрированных на основе функций на основе последовательностей, с выбором функции mRMR. Научный представитель 6 , 38318 (2016).
Артикул PubMed PubMed Central ОБЪЯВЛЕНИЯ CAS Google Scholar
Хасан М. М. и др. . Вычислительная идентификация сайтов пупилирования белков с помощью составления на основе профиля k-разнесенных аминокислотных пар. PLoS One 10 , e0129635 (2015).
Артикул PubMed PubMed Central CAS Google Scholar
Цао, Д. С., Сюй, К. С. и Лян, Ю. З. propy: инструмент для создания различных режимов PseAAC Чжоу. Биоинформатика 29 , 960–962 (2013).
Артикул PubMed CAS Google Scholar
Saha, I., Maulik, U., Bandyopadhyay, S. & Plewczynski, D. Нечеткая кластеризация физико-химических и биохимических свойств аминокислот. Аминокислоты 43 , 583–594 (2012).
Артикул PubMed CAS Google Scholar
Блабер М., Чжан Х. Дж. И Мэтьюз Б. В. Структурные основы склонности аминокислот к альфа-спирали. Наука 260 , 1637–1640 (1993).
Артикул PubMed ОБЪЯВЛЕНИЯ CAS Google Scholar
Биу В., Гибрат Дж. Ф., Левин Дж. М., Робсон Б. и Гарнье Дж. Предсказание вторичной структуры: комбинация трех различных методов. Protein Eng 2 , 185–191 (1988).
Артикул PubMed CAS Google Scholar
Максфилд, Ф. Р. и Шерага, Х. А. Статус эмпирических методов прогнозирования топографии белкового остова. Биохимия 15 , 5138–5153 (1976).
Артикул PubMed CAS Google Scholar
Цай, Дж., Тейлор, Р., Чотиа, К. и Герштейн, М. Плотность упаковки в белках: стандартные радиусы и объемы. J Mol Biol 290 , 253–266 (1999).
Артикул PubMed CAS Google Scholar
Накашима, Х. и Нишикава, К. Аминокислотный состав цитоплазматической и внеклеточной сторон белков мембран различается. FEBS Lett 303 , 141–146 (1992).
Артикул PubMed CAS Google Scholar
Cedano, J., Aloy, P., Perez-Pons, J. A. & Querol, E. Связь между аминокислотным составом и клеточным расположением белков. J Mol Biol 266 , 594–600 (1997).
Артикул PubMed CAS Google Scholar
Lifson, S. & Sander, C. Антипараллельные и параллельные бета-цепи различаются по предпочтениям аминокислотных остатков. Nature 282 , 109–111 (1979).
Артикул PubMed ОБЪЯВЛЕНИЯ CAS Google Scholar
Миядзава, С. и Джерниган, Р. Л. Самосогласованная оценка энергии контакта белков между остатками на основе приближения остатков равновесной смеси. Белки 34 , 49–68 (1999).
Артикул PubMed CAS Google Scholar
Даскалаки, С., Копанас, И. и Авурис, Н. Оценка классификаторов для задачи неравномерного распределения классов. Прикладной искусственный интеллект 20 , 381–417 (2006).
Артикул Google Scholar
Хе, Х. и Гарсия, Э. А. Обучение на несбалансированных данных. IEEE Transactions по знаниям и инженерии данных 21 , 1263–1284 (2009).
Артикул Google Scholar
Явуз, А. С. и Сезерман, О. У. Прогнозирование сайтов сумоилирования с использованием опорных векторных машин на основе различных характеристик последовательности, конформационной гибкости и беспорядка. BMC Genomics 15 (Приложение 9), S18 (2014).
Артикул PubMed PubMed Central Google Scholar
Yan, R. X., Si, J. N., Wang, C. & Zhang, Z. DescFold: веб-сервер для распознавания белковых складок. BMC Bioinformatics 10 , 416 (2009).
Артикул PubMed PubMed Central CAS Google Scholar
Чанг, C.-C. И Лин, К.-Дж. LIBSVM: библиотека для поддержки векторных машин. транзакций ACM по интеллектуальным системам и технологиям (TIST) 2 , 27 (2011).
Google Scholar
Фосетт, Т. Введение в ROC-анализ. Письма для распознавания образов 27 , 861–874 (2006).
Артикул Google Scholar
Hanley, J. A. & McNeil, B.J. Значение и использование площади под кривой рабочей характеристики приемника (ROC). Радиология 143 , 29–36 (1982).
Артикул PubMed CAS PubMed Central Google Scholar
Теоретическая характеристика выбора функций на основе линейной SVM – Experts @ Minnesota
TY – GEN
T1 – Теоретическая характеристика выбора функций на основе линейной SVM
AU – Hardin, Douglas
AU – Tsamardinos, Ioannis
AU – Алиферис, Константин Ф.
PY – 2004/12/1
Y1 – 2004/12/1
N2 – Наиболее распространенные методы выбора функций машины опорных векторов (SVM) основаны на интуиции, что веса функций, близкие к нулю, равны не требуется для оптимальной классификации. В этой статье мы показываем, что действительно в пределе выборки нерелевантным переменным (в теоретическом и оптимальном смысле) будет присвоен нулевой вес с помощью линейного SVM, как в случае мягкого, так и жесткого запаса. Однако методы на основе SVM имеют и определенные теоретические недостатки.Мы представляем примеры, в которых линейная SVM может присваивать нулевые веса сильно релевантным переменным (т. Е. Переменным, необходимым для оптимальной оценки распределения целевой переменной) и где слабо релевантные признаки (т. Е. Признаки, которые являются лишними для оптимального выбора признаков с учетом других признаков ) могут иметь ненулевые веса. Мы противопоставляем и теоретически сравниваем алгоритмы выбора признаков на основе Маркова-Бланкета, которые не имеют таких недостатков в широком классе распределений и могут также использоваться для выявления причин.
AB – Наиболее распространенные методы выбора признаков с помощью машины опорных векторов (SVM) основаны на интуиции, что веса признаков, близкие к нулю, не требуются для оптимальной классификации. В этой статье мы показываем, что действительно в пределе выборки нерелевантным переменным (в теоретическом и оптимальном смысле) будет присвоен нулевой вес с помощью линейного SVM, как в случае мягкого, так и жесткого запаса. Однако методы на основе SVM имеют и определенные теоретические недостатки. Мы представляем примеры, в которых линейная SVM может присваивать нулевые веса сильно релевантным переменным (т.е., переменные, необходимые для оптимальной оценки распределения целевой переменной), и где слабо релевантные характеристики (т. е. особенности, которые являются лишними для оптимального выбора характеристик с учетом других характеристик) могут иметь ненулевые веса. Мы противопоставляем и теоретически сравниваем алгоритмы выбора признаков на основе Маркова-Бланкета, которые не имеют таких недостатков в широком классе распределений и могут также использоваться для выявления причин.