
Список должностей по классификатору 2019: , 016-94 () ( 26 1994 . N 367) ( )
Перечень профессий и должностей, требующих профессионального обучения, будет актуализирован
20.12.2019
13 декабря в Национальном агентстве развития квалификаций (АНО «НАРК») состоялось Всероссийское совещание по вопросам обновления структуры и содержания Перечня профессий рабочих и должностей служащих, по которым осуществляется профессиональное обучение.
В совещании очно и в режиме вебинара приняли участие более 200 человек – представители органов государственной власти, системы образования, работодателей, советов по профессиональным квалификациям, общественных организаций. Это свидетельствует о высоком интересе к, казалось бы, узкопрофессиональной теме.
Заместитель директора Департамента государственной политики в сфере профессионального образования и опережающей подготовки кадров Министерства просвещения РФ Наталья Бебенина отметила, что актуализация Перечня должна проходить совместно со всеми заинтересованными участниками рынка.
Обновление перечня обусловлено появлением современного способа описания квалификаций – профессиональных стандартов. Заместитель генерального директора АНО «НАРК» Алла Факторович напомнила, что первый постсоветский перечень появился в 2001 году. С тех пор его структура менялась дважды, но всякий раз ее основанием оставался общероссийский классификатор профессий рабочих, должностей служащих и тарифных разрядов, который сегодня теряет актуальность.
Алла Факторович проанализировала три возможных сценария актуализации структуры и содержания перечня, подчеркнув, что при реализации любого из них перечень должен обновляться с учетом сигналов с рынка труда, быстро включать новые позиции и исключать устаревшие.
При этом, по ее мнению, нужно отличать истинные сигналы от ложных, а ложных сигналов немало. Так, в Атласе новых профессий 2014 года содержался прогноз, что целый ряд профессий (гмо-агроном, архитектор живых систем, ИТ-проповедник и другие) к 2020 году станут частью нашей жизни и потребуют роста объемов подготовки кадров, но в Атласе 2018 года этот прогноз «сдвинут» на 10 лет.
«Даже в цифровую эпоху «поспешать» нужно медленно, отличая действительно новые профессии от эволюционирующих», – пояснила Алла Факторович.
На совещании также выступили генеральный директор АНО «НАРК» Александр Лейбович, первый заместитель генерального директора АНО «НАРК» Юлия Смирнова, ответственный секретарь Совета по профессиональным квалификациям в области сварки Александр Чупрак, начальник отдела мониторинга квалификации персонала Корпоративного центра развития профессионального обучения персонала ОАО «РЖД»

Профессиональное обучение – это массовые короткие программы, призванные быстро реагировать на запросы работодателей. Несмотря на то, что содержание этих программ определяется динамикой развития рынка труда, механизмы их регулирования со стороны государства существовали всегда. Сейчас необходимо оценить эти механизмы, понять, где они приносят пользу, а где, возможно, создают дополнительные барьеры. Таким образом, программы профессионального обучения получат новый импульс к развитию и будут синхронизированы с инструментами Национальной системы квалификаций.
Классификатор должностей и профессий ОКПДТР с расшифровкой — Контур.Персонал — СКБ Контур
ОКПДТР был принят постановлением Госстандарта РФ от 26 декабря 1994 года № 367.
Классификатор профессий и должностей состоит из двух разделов: профессии рабочих и должности служащих.
Должности предусмотрены для сотрудников, занимающихся, в первую очередь, умственным трудом. Согласно классификации ОКПДТР, сюда относят руководителей, специалистов и других служащих. В ОКПДТР включены профессии в соответствии с Единым тарифно-квалификационным справочником работ и профессий рабочих (ЕТКС), а также профессии рабочих, права и обязанности которых предусмотрены в уставах, специальных положениях и соответствующих постановлениях, регламентирующих состав профессий в отраслях экономики.
В ОКПДТР включены профессии в соответствии с Единым тарифно-квалификационным справочником работ и профессий рабочих (ЕТКС), а также профессии рабочих, права и обязанности которых предусмотрены в уставах, специальных положениях и соответствующих постановлениях, регламентирующих состав профессий в отраслях экономики.
Профессии предусмотрены для сотрудников, занимающихся преимущественно физическим трудом. Согласно классификатору ОКПДТР, сюда относят рабочих.
Для должностей и профессий предусмотрены фасеты, характеризующие должности и профессии по различным признакам.
Для должностей служащих предусмотрены следующие фасеты:
- Фасет 10 — категории должностей: руководители, специалисты, другие служащие.
- Фасет 11 — производные должности, например, заместитель, главный, ведущий и т д.
- Фасет 12 — категории (классы) квалификации: с 6 по 1 категории, включая высшую категорию.
Для профессий рабочих предусмотрены следующие фасеты:
- Фасет 01 — виды производств и работ в соответствии с выпусками ЕТКС.

- Фасет 02 — тарифные разряды: с 1 по 8 разряд.
- Фасет 03 — классы (категории) квалификации: с 1 по 3 класс.
- Фасет 04 — формы и системы оплаты труда, например, сдельная, прогрессивная.
- Фасет 05 — условия труда, например, нормальные, тяжелые и вредные.
- Фасет 06 — степень механизации труда, например, выполнение работ вручную или при помощи машин и механизмов.
- Фасет 07 — производные профессии, например, помощник или старший.
В программе Контур-Персонал вы можете формировать такие отчеты, как 1-кадры (Росстат), форма №6 (воинский учет), перечень льготных профессий, РСВ-1 и пр.
Попробовать бесплатноДокументы – Правительство России
Постановления от 29 ноября 2018 года №1440, №1441. С 1 января 2019 года на 25% будет увеличена фиксированная выплата к страховой пенсии пенсионерам, имеющим стаж работы в сельском хозяйстве не менее 30 лет и проживающим в сельской местности. Подписанными постановлениями утверждены список работ, производств, профессий, должностей, специальностей, в соответствии с которыми устанавливается повышение фиксированной выплаты, правила исчисления периодов соответствующей работы, правила установления и выплаты такого повышения.
Подписанными постановлениями утверждены список работ, производств, профессий, должностей, специальностей, в соответствии с которыми устанавливается повышение фиксированной выплаты, правила исчисления периодов соответствующей работы, правила установления и выплаты такого повышения.
Справка
Внесены Минтрудом России.
Документы
Постановление от 29 ноября 2018 года №1440
Постановление от 29 ноября 2018 года №1441
Федеральным законом
от 3 октября 2018 года №350-ФЗ были внесены изменения в Федеральный закон «О страховых пенсиях», в
соответствии с которыми с 1 января 2019 года на 25% будет увеличена
фиксированная выплата к страховой пенсии пенсионерам, имеющим стаж работы в
сельском хозяйстве не менее 30 лет и проживающим в сельской местности. Установление такого повышения фиксированной выплаты предусмотрено частью 14
статьи 17 Федерального закона «О
страховых пенсиях».
Установление такого повышения фиксированной выплаты предусмотрено частью 14
статьи 17 Федерального закона «О
страховых пенсиях».
Постановлением №1440 утверждён
список работ, производств, профессий, должностей, специальностей, в
соответствии с которыми устанавливается повышение на 25% размера фиксированной
выплаты к страховой пенсии по старости и к страховой пенсии по инвалидности
неработающим пенсионерам, проработавшим не менее 30 календарных лет в сельском
хозяйстве и проживающим в сельской местности (далее соответственно – Список,
фиксированная выплата). Список основывается на Общероссийском классификаторе
видов экономической деятельности, едином тарифно-квалификационном справочнике
работ и профессий рабочих, Общероссийском классификаторе профессий рабочих,
должностей служащих и тарифных разрядов, а также на предложениях Минсельхоза
России. Отдельные профессии и специальности объединены под общим наименованием.
Например, профессия «дояр(ка)» включена в категорию «Рабочие всех наименований».
Также утверждены правила исчисления периодов соответствующей работы. В соответствии с этими правилами в стаж работы в сельском хозяйстве будут включаться периоды работы (деятельности) на территории Российской Федерации и территории СССР до 1 января 1992 года при условии занятости в производствах, профессиях, должностях, специальностях, предусмотренных Списком. Работа в сельском хозяйстве на территории РСФСР до 1 января 1992 года будет включаться в соответствующий стаж вне зависимости от наименования профессии, специальности или занимаемой должности.
В стаж работы в сельском хозяйстве будут также засчитываться периоды получения пособия по обязательному социальному страхованию в период временной нетрудоспособности, ежегодных оплачиваемых отпусков и ухода одного из родителей за каждым из детей до достижения ими возраста полутора лет, но не более шести лет в общей сложности.
Определён также порядок подтверждения стажа работы в сельском хозяйстве.
***
Постановлением №1441 утверждены Правила установления и выплаты повышения
фиксированной выплаты к страховой пенсии лицам, проработавшим не менее 30
календарных лет в сельском хозяйстве, проживающим в сельской местности (далее –
Правила).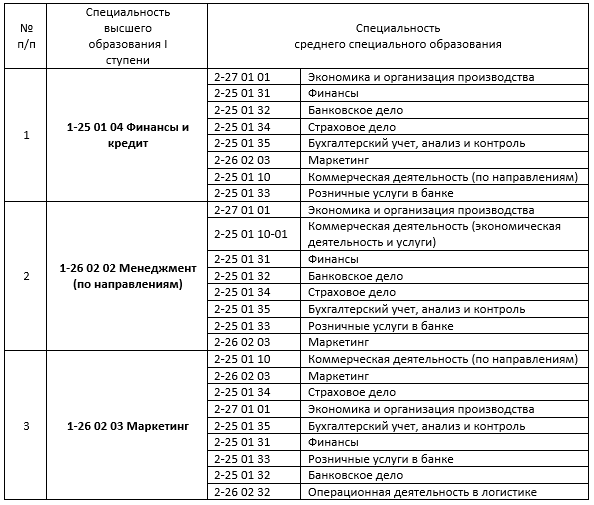
Правилами предусматривается, что стаж работы в сельском хозяйстве для определения права на повышение фиксированной выплаты будет исчисляться в соответствии с правилами подсчёта соответствующего стажа, утверждёнными постановлением №1440.
Действие Правил распространяется на российских граждан, зарегистрированных по месту жительства (пребывания), фактического проживания (при отсутствии такой регистрации) в сельской местности, и иностранных граждан и лиц без гражданства, постоянно проживающих в сельской местности. При отнесении местности к сельской для установления повышения фиксированной выплаты будет применяться раздел «Сельские населённые пункты» Общероссийского классификатора объектов административно-территориального деления.
В соответствии с Правилами повышение фиксированной выплаты будет устанавливаться территориальным органом Пенсионного фонда и выплачиваться одновременно со страховой пенсией.
Определены
порядок и сроки перерасчёта размера фиксированной выплаты в тех случаях, когда
её повышение не устанавливается: при переезде пенсионера на новое место
жительства за пределы сельской местности и (или) поступлении на работу и (или)
осуществлении другой деятельности, в период которой застрахованное лицо
подлежит обязательному пенсионному страхованию.
Утверждённые Список и правила будут применяться с 1 января 2019 года – даты вступления в силу части 14 статьи 17 Федерального закона «О страховых пенсиях».
Классификаторы и справочники
19.07.2021 Q018 Описание правил заполнения элементов файлов информационного обмена при ведении персонифицированного учета сведений об оказанной медицинской помощи
временный, до выхода официальной версии
15.01.2021 ГРУППИРОВЩИК КСГ. МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ ПО СПОСОБАМ ОПЛАТЫ МЕДИЦИНСКОЙ ПОМОЩИ ЗА СЧЕТ СРЕДСТВ ОБЯЗАТЕЛЬНОГО МЕДИЦИНСКОГО СТРАХОВАНИЯ.
26.08.2016 T001 – Коды видов территориальной программы
26.02.2021 T002 – Признак “Особый случай”
15.07.2021 Т003 – Территориальный классификатор услуг
15. 07.2021 Справочник соответствия _Т003_V010_T002_V025
07.2021 Справочник соответствия _Т003_V010_T002_V025
26.07.2021 тарифы и коэффициенты на 3кв 2021г
06.07.2021 Справочник ФАП с LPU_1
08.02.2021 T004 – Коды льготных категорий граждан при реализации мер социальной поддержки
T005 – Код врача
Перейти в закрытый раздел сайта для скачивания справочника
Внимание: справочник обновляется с 5 по 25 число каждого месяца. В период сдачи реестров (с 25 по 5) справочники не обновляются.
Письмо Минздрава России от 08.04.2020 № 13-2/И/2-4335 о кодировании статистической информации_COVID-19
30.06.2021 Тестовый справочник лицензий
05.07.2021 Т007 – Справочник кодов адресов отделений
LPU_1
21. 06.2021 Т013 – Справочник кодов отделений
06.2021 Т013 – Справочник кодов отделений
16.07.2021 T014 – Справочник типов реестров
03.07.2020 Незастрахованные, допустимые коды услуг
27.04.2021 Т016 КСЛП Коэффициент сложности лечения пациента
07.02.2020 Соответствие видов медицинской помощи (V008-VIDPOM) условиям оказания медицинской помощи (V006-USL_OK) с указанием медицинской специальности (PRVS)
26.09.2016 Классификатор муниципальных образований Тюменской области
05.02.2021 T017
01.02.2019 V001 – Номенклатура медицинских услуг (вид медицинского вмешательства)
30.03.2018 V002 – Классификатор профилей оказанной медицинской помощи
30. 03.2018 V003 – Классификатор работ (услуг) при лицензировании медицинской помощи
02.04.2018 V005 – Классификатор пола застрахованного
13.12.2017 V006 – Классификатор условий оказания медицинской помощи
06.05.2020 V008 – Классификатор видов медицинской помощи
28.06.2019 V009 Классификатор результатов обращения за медицинской помощью
11.01.2019 V010 – Классификатор способов оплаты медицинской помощи
11.04.2018 V011 – Государственный реестр лекарственных средств
Перейти на сайт Министерства Здравоохранения РФ
13.12.2017 V012 – Классификатор исходов заболеваний
05. 09.2018 V013 – Классификатор категорий застрахованного лица
09.2018 V013 – Классификатор категорий застрахованного лица
15.12.2017 V014 – Классификатор форм оказания медицинской помощи
03.08.2021 V016 – Классификатор типов диспансеризации
03.08.2021 V017 – Классификатор результатов диспансеризации
26.01.2021 V018 – Классификатор видов высокотехнологичной медицинской помощи
25.03.2021 V019 – Классификатор методов высокотехнологичной
версия 6.1
19.12.2017 V020 – Классификатор профилей коек
26.05.2020 V021 Классификатор медицинских специальностей
16.01.2020 V022 Классификатор моделей пациента при оказании ВМП
30. 12.2020 V023 Классификатор клинико-статистические группы
12.2020 V023 Классификатор клинико-статистические группы
13.01.2021 V023 Классификатор клинико-статистические группы
30.12.2020 V024 Классификатор классификационных критериев (DopKr)
13.01.2021 V024 Классификатор классификационных критериев (DopKr)
13.04.2018 V025 Классификатор целей посещения
24.12.2019 V026 Классификатор клинико-профильных групп (KPG)
26.09.2018 V027 Характер заболевания (C_ZAB)
26.09.2018 V028 Классификатор видов направления (NAPR_V)
26.09.2018 V029 Классификатор методов диагностического исследования (MET_ISSL)
N_ Классификаторы по онкологии
19. 11.2018 N001 Код противопоказания или отказа
11.2018 N001 Код противопоказания или отказа
Справочники 1 – 50 из 369
Начало | Пред. | 1 2 3 4 5 | След. | Конец
Письмо Минсоцполитики N 21/0/191-19 от 07.02.2019 г. «Об определении названия должности»-Профи Винс
МИНИСТЕРСТВО СОЦИАЛЬНОЙ ПОЛИТИКИ УКРАИНЫ
ПИСЬМО
от 07.02.2019 г. N 21/0/191-19
Об определении названия должностиВ Директорате развития рынка труда и занятости рассмотрено ваше обращение и сообщается.
Названия должностей (профессий), которые предполагается использовать в штатном расписании предприятий, учреждений и организаций, определяются согласно Национальному классификатору Украины ДК 003:2010 “Классификатор профессий”, утвержденному приказом Госпотребстандарта от 28.07.2010 г. N 327 (с изменениями) (далее – Классификатор профессий).
В случае отсутствия в Классификаторе профессий названия должности, которая полностью соответствует возложенным на работника обязанностям, выбирается ближайшее по содержанию название, а в должностной инструкции работника указываются все особенности работы по этой должности.
Так, в Классификаторе профессий предусмотрено название должностей “Консультант” с кодом 2419.2 (профессиональная группировка “Профессионалы в сфере маркетинга, эффективности хозяйственной деятельности, рационализации производства, интеллектуальной собственности и инновационной деятельности”), “Аудитор” и “Консультант по налогам и сборам” с кодом 2411.2 (профессиональная группировка “Аудиторы и квалифицированные бухгалтеры”).
Классификатором профессий также предусмотрены правила расширения (уточнения) названий должностей (профессий) (Приложение В Классификатора).
В соответствии с примечанием 2 Приложения В к Классификатору профессий при наличии у пользователя потребности в расширении названий должностей (профессий) могут использоваться термины и слова, уточняющие место работы, выполняемые работы, сферу деятельности при условии соблюдения лаконичности изложения.
Во время образования расширенных названий должностей (профессий) сохраняется код базовой должности (профессии).
Таким образом, от указанных названий должностей могут образовываться названия “Консультант в сфере налогообложения и бухгалтерского учета” (код 2419.2), “Аудитор в области налогообложения и бухгалтерского учета” (код 2411.2) и “Консультант по налогам и сборам и бухгалтерскому учету” (код 2411.2).
Следует отметить, что согласно нормам статьи 64 Хозяйственного кодекса Украины касательно самостоятельности предприятия относительно определения своей организационной структуры, численности работников и штатного расписания работодателю предоставляется право самостоятельно определять названия должностей (профессий), применяемых в штатном расписании, но эти названия должны соответствовать Классификатору профессий.
Конкретный перечень должностных обязанностей определяется должностными инструкциями работников на основе квалификационной характеристики ближайшего по своим обязательствам профессионального названия работы или с учетом разделения труда, задач и обязанностей, планирующихся или фактически сложившихся между работниками в рабочем процессе.
Одновременно отмечаем, что письма Министерства не являются нормативно-правовыми актами, по своей природе они носят информационный, разъяснительный и рекомендательный характер и не устанавливают новых правовых норм.
Генеральный директор | О. Савенко |
Добавить комментарий
| < Предыдущая | Следующая > |
|---|
Новый классификатор должностей и профессий: разъяснение – Газета.uz
Фото: Минтрудсоцзащиты
В обновленный классификатор основных должностей служащих и профессий рабочих внесены 566 новых должностей и профессий.
 8 июля 2015, 07:32
Экономика
8 июля 2015, 07:32
Экономика Министерством труда и социальной защиты населения Узбекистана разработан новый классификатор должностей и профессий. 19 июня он был утвержден постановлением Кабинета Министров. Информационная служба Минтрудсоцзащиты подготовила разъяснение об изменениях в классификаторе.
Что это?
- Классификатор вводит стандарты наименований должностей и профессий при составлении трудового договора, штатного расписания, внесения записей в трудовые книжки, оформления приказов по трудовым отношениям, отнесение должностей и профессий к соответствующим категориям персонала.
- Классификатор является ориентиром для подготовки профессиональных кадров новой формации, в том числе в сфере корпоративного управления.
- Классификатор является инструментом для эффективной расстановки кадров с учетом уровня образования и квалификационной категории.
- Обновленный классификатор состоит из трех частей: нормативной, определяющей порядок его применения, и двух классификационных (Раздел 1 — профессии рабочих и Раздел 2 — должности служащих), определяющих наименования основных должностей и профессий, а также их основные квалификационные характеристики и требования.
Что нового?
- В обновленный классификатор основных должностей служащих и профессий рабочих внесены 566 новых должностей и профессий.
- 74 должности направлены на кадровое обеспечение современной структуры корпоративного управления акционерными обществами (определенна указом Президента от 24 апреля «О мерах по внедрению современных методов корпоративного управления в акционерных обществах»).
- 54 должности обеспечивают дальнейшее развитие рыночной инфраструктуры.
- 22 должности направлены на развитие сферы информационно-коммуникационных технологий.
- 383 новые производственные должности и профессии введены по предложениям органов государственного и хозяйственного управления.
- Общее количество должностей и профессий в обновленном классификаторе — 8395 единицы, в том числе 5538 должностей служащих и 2857 профессий рабочих.

Применение классификатора
- Каждая профессия и должность, указанная в обновленном классификаторе, увязана с направлением профессиональной подготовки среднего специального, профессионального или высшего образования. Это обеспечит его сопряженность с системой подготовки кадров Узбекистана и профессионально-должностной структуры экономики.
- Для упорядочения базовых квалификационных требований по рабочим профессиям с учетом их сложности в обновленном классификаторе по каждой рабочей профессии указан диапазон тарифно-квалификационных разрядов.
Действие обновленного классификатора является обязательным:
- в части использования наименований должностей служащих и профессий рабочих при производстве записей в трудовые книжки работников, заключении трудовых договоров, оформлении приказов, отнесении должностей служащих к категориям персонала — для всех организаций, действующих на территории Узбекистана;
- в части определения минимального уровня при приеме на работу, установления тарифных разрядов по профессиям рабочих ОКОДП — для применения в государственных организациях, органах хозяйственного управления, созданных решениями Президента и Кабинета Министров, а также организациях с долей государства в уставном капитале более 50%; для других организаций носит рекомендательный характер;
- в части направлений образования — носит рекомендательный характер для всех организаций.

На основе обновленного классификатора будет разработан межотраслевой тарифно-квалификационный справочник по основным должностям служащих и профессий рабочих, являющихся общими для всех отраслей и сфер экономики Узбекистана.
Намечено создание сети региональных и отраслевых центров по присвоению и подтверждению квалификационных разрядов по профессиям рабочих.
Обновленный классификатор основных должностей служащих и профессий рабочих вступил в действие с 1 июля. Записи в трудовых книжках работников и локальных трудовых актах организаций, произведенные до 1 июля 2015 года, сохраняют силу.Подпишитесь на наш Telegram
Справочник должностных инструкций 2019
Статья акутальна на: Август 2021 г.
В настоящем разделе представлены выпуски единого квалификационного справочника должностей руководителей, специалистов и других служащих (далее — ЕКС). ЕКС предназначен для тарификации работ и присвоения тарифных разрядов. На основе ЕКС возможно составление должностных инструкций и программ по подготовке и повышению квалификации специалистов в различных отраслях и сферах деятельности. Раздел обновлен 17 октября 2018 года — добавленые выпуски, исправлены технические ошибки.
На основе ЕКС возможно составление должностных инструкций и программ по подготовке и повышению квалификации специалистов в различных отраслях и сферах деятельности. Раздел обновлен 17 октября 2018 года — добавленые выпуски, исправлены технические ошибки.
Постановлением Правительства РФ от 31.10.2002 N 787 установлено, что ЕКС состоит из квалификационных характеристик должностей руководителей, специалистов и служащих, содержащих должностные обязанности и требования, предъявляемые к уровню знаний и квалификации руководителей, специалистов и служащих.
Разработкой ЕКС занимается Министерство здравоохранения и социального развития РФ совместно с федеральными органами исполнительной власти, на которые возложены управление, регулирование и координация деятельности в соответствующей отрасли (подотрасли) экономики (пункт 2 Постановления Правительства РФ от 31.10.2002 N 787). Постановлением Минтруда РФ от 09.02.2004 N 9 утвержден Порядок применения ЕКС.
В данной разделе приведен перечень действующих на территории Российской Федерации выпусков ЕКС, актуальных на 15. 06.2014 года. Обращаем ваше внимание также на то, что часто этот справочник ошибочно называют ЕТКС должностей руководителей и специалистов (см. ЕТКС работ и профессий рабочих).
06.2014 года. Обращаем ваше внимание также на то, что часто этот справочник ошибочно называют ЕТКС должностей руководителей и специалистов (см. ЕТКС работ и профессий рабочих).
Содержание статьи
Должности по алфавиту
Если вы знаете название должности по справочнику, но не знаете, в каком разделе ЕКС она описана, тогда для быстрого поиска ее описания можно воспользоваться алфавитным указателем:
Статьи по теме (кликните, чтобы посмотреть)
Перечь должностей по разделам справочника
| Наименование раздела ЕКС | Утверждающий документ |
| Общеотраслевые квалификационные характеристики должностей работников, занятых на предприятиях, в учреждениях и организациях | Постановление Минтруда РФ от 21.08.1998 N 37 |
| Квалификационные характеристики должностей работников, занятых в научно-исследовательских учреждениях, конструкторских, технологических, проектных и изыскательских организациях | |
| Квалификационный справочник должностей руководителей и специалистов организаций геологии и разведки недр | Постановление Минтруда РФ от 20.12.2002 N 82 |
| Квалификационные характеристики должностей работников центров стандартизации, метрологии и сертификации, уполномоченных осуществлять государственный контроль и надзор | Постановление Минтруда РФ от 29.01.2004 N 5 |
| Квалификационный справочник должностей руководителей, специалистов и других служащих организаций электроэнергетики | Постановление Минтруда РФ от 29.01.2004 N 4 |
| Квалификационные характеристики должностей руководителей и специалистов архитектуры и градостроительной деятельности | Приказ Минздравсоцразвития РФ от 23.04.2008 N 188 |
| Квалификационные характеристики должностей работников учреждений системы государственного материального резерва | Приказ Минздравсоцразвития РФ от 05.05.2008 N 220 |
| Квалификационные характеристики должностей специалистов, осуществляющих комплекс работ в области правовой охраны результатов интеллектуальной деятельности и средств индивидуализации | Приказ Минздравсоцразвития РФ от 23.07.2008 N 347 |
| Квалификационные характеристики должностей работников учреждений органов по делам молодежи | Приказ Минздравсоцразвития РФ от 28.11.2008 N 678 |
| Квалификационные характеристики должностей руководителей и специалистов организаций воздушного транспорта | Приказ Минздравсоцразвития РФ от 29.01.2009 N 32 |
| Квалификационные характеристики должностей руководителей и специалистов организаций дорожного хозяйства | Приказ Минздравсоцразвития РФ от 16.02.2009 N 47 |
| Квалификационные характеристики должностей работников гидрометеорологической службы | Приказ Минздравсоцразвития РФ от 16.02.2009 N 48 |
| Квалификационные характеристики должностей работников территориальных органов Федеральной миграционной службы | Приказ Минздравсоцразвития РФ от 11.03.2009 N 107 |
| Квалификационные характеристики должностей руководителей и специалистов по обеспечению безопасности информации в ключевых системах информационной инфраструктуры, противодействию техническим разведкам и технической защите информации | Приказ Минздравсоцразвития РФ от 22.04.2009 N 205 |
| Квалификационные характеристики отдельных категорий работников Государственной противопожарной службы Министерства Российской Федерации по делам гражданской обороны, чрезвычайным ситуациям и ликвидации последствий стихийных бедствий | Приказ Минздравсоцразвития РФ от 24.11.2009 N 919 |
| Квалификационные характеристики должностей работников организаций атомной энергетики | Приказ Минздравсоцразвития РФ от 10.12.2009 N 977 |
| Квалификационная характеристика должности «Конфликтолог» | Приказ Минздравсоцразвития РФ от 22.12.2009 N 1007 |
| Квалификационные характеристики должностей работников в сфере здравоохранения | Приказ Минздравсоцразвития РФ от 23.07.2010 N 541н |
| Квалификационные характеристики должностей работников в сфере образования | Приказ Минздравсоцразвития РФ от 26.08.2010 N 761н |
| Квалификационные характеристики должностей руководителей и специалистов высшего профессионального и дополнительного профессионального образования | Приказ Минздравсоцразвития РФ от 11.01.2011 N 1н |
| Квалификационные характеристики должностей работников культуры, искусства и кинематографии | Приказ Минздравсоцразвития РФ от 30.03.2011 N 251н |
| Квалификационные характеристики должностей работников в области физической культуры и спорта | Приказ Минздравсоцразвития РФ от 15.08.2011 N 916н |
| Квалификационные характеристики должностей работников сельского хозяйства | Приказ Минздравсоцразвития РФ от 15.02.2012 N 126н |
| Квалификационные характеристики должностей работников организаций сферы туризма | Приказ Минздравсоцразвития РФ от 12.03.2012 N 220н |
| Квалификационные характеристики должностей работников организаций ракетно-космической промышленности | Приказ Минздравсоцразвития РФ от 10.04.2012 N 328н |
| Квалификационные характеристики должностей работников государственных архивов, центров хранения документации, архивов муниципальных образований, ведомств, организаций, лабораторий обеспечения сохранности архивных документов | Приказ Минздравсоцразвития РФ от 11.04.2012 N 338н |
| Квалификационные характеристики должностей специалистов, осуществляющих работы в сфере переводческой деятельности | Приказ Минздравсоцразвития РФ от 16.05.2012 N 547н |
| Квалификационные характеристики должностей специалистов, осуществляющих работы в области охраны труда | Приказ Минздравсоцразвития РФ от 17.05.2012 N 559н |
| Квалификационные характеристики должностей специалистов, осуществляющих работы в области судебной экспертизы | Приказ Минздравсоцразвития РФ от 16.05.2012 N 550н |
| Квалификационные характеристики должностей работников, осуществляющих деятельность в области гражданской обороны, защиты населения и территорий от чрезвычайных ситуаций природного и техногенного характера, обеспечения пожарной безопасности, безопасности людей на водных объектах и объектах ведения горных работ в подземных условиях | Приказ Минтруда России от 03.12.2013 N 707н |
Скачать все выпуски ЕКС одним архивом с нашего сайта, к сожалению, на данный момент нельзя. Однако можно найти интересующие вас должности с помощью алфавитного указателя должностей или рубрикатора действующих на территории РФ выпусков ЕКС.
Значение единого квалификационного справочника должностей рабочих и служащих (ЕКСД) в 2021 году
С 1.07.2016 в трудовой сфере используют единые профстандарты, когда требования к рабочей квалификации для исполнения трудовой функции определены ТК РФ или иными нормативами. Каково значение ЕКСД?
По существующему трудовому законодательству тарифицирование работ, а также определение тарифных разрядов сотрудников происходит соответственно профстандартам и положениям специальных справочников.
Дорогие читатели! Статья рассказывает о типовых способах решения юридических вопросов, но каждый случай индивидуален. Если вы хотите узнать, как решить именно Вашу проблему — обращайтесь к консультанту:
ЗАЯВКИ И ЗВОНКИ ПРИНИМАЮТСЯ КРУГЛОСУТОЧНО и БЕЗ ВЫХОДНЫХ ДНЕЙ.
Это быстро и БЕСПЛАТНО!
Так Постановлением Правительства Российской федерации № 787 определено, что именно Единый квалификационный справочник должностей рабочих и служащих определяет характеристики касательно должностей и устанавливает требования к уровню познаний и квалификации.
Правила по использованию ЕКС установлены Постановлением Минтруда № 9 от 9.02.2004.
Назначение документа
Общероссийский ЕКС применяют при создании инструкций к должностям и программ, касающихся подготовки сотрудников или повышения уже имеющейся квалификации. Кроме прочего ЕКС применяют для тарифицирования трудовой деятельности и присвоения тарифных разрядов.
Характеристики должностей, которые применялись ранее, были утверждены больше десяти лет назад. Они соответствовали экономическим и организационно-техническим условиям, которые действовали на момент разработки.
Потому организация труда и разделение должностей на основании устаревших норм не отвечает современным условиям хозяйствования и безопасности. Это было учтено при создании нового Справочника.
Назначением нового ЕКС стала необходимость устранения существующих недостатков и пробелов. Справочник можно скачать здесь.
Изменения, произошедшие в сфере экономики, социума, организационного порядка и технической оснащенности, обусловили потребность в пересмотре характеристик по должностям исходя их современных требований к персоналу.
Ныне функционирующий Справочник включает в себя обновленные характеристики специальностей сотрудников, чьи трудовые функции касаются установления и последующего развития экономических отношений.
Так за последние десятилетия появилось немало относительно новых профессий, которые ранее были мало распространены или вовсе отсутствовали.
И для таких должностей должны быть приняты требования, отвечающие государственным задачам и реформам. Основополагающие функции, которые обеспечивает ЕКС, это:
| Рациональное разделение | Трудовых обязанностей |
| Адекватное разграничивание полномочий | Должностных функций и персональной ответственности |
| Четкое регламентирование трудовой деятельности | Сотрудников в изменившихся условиях рынка |
Утверждение новых квалификационных характеристик призвано:
| Организовать трудовой процесс | С наибольшей рациональностью для производства |
| Обеспечить правильное использование кадров | Их подбор и расстановку |
| Конкретизировать должностные обязанности сотрудников | И уточнить требования к их квалификации |
| Убедиться в соответствии руководителей | И специалистов занимаемым должностям при проведении аттестации персонала |
ЕКС – это норматив, который отвечает всем современным условиям и вместе с тем обеспечивает преемственность с ранее существовавшими нормативами.
Структура ЕКСД
Все положения документа построены на основании должностных признаков, потому как требования к рабочей квалификации обусловлены трудовыми обязанностями. Вместе с тем обязанности сотрудников зависят от названия конкретных должностей.
При разработке Справочника было учтено категориальное деление служащих. В частности это руководящий состав, специалисты и остальные служащие.
Для того чтобы классифицировать служащих по отдельным категориям учитывают характер осуществляемых работ и содержание рабочих функций работников.
Названия должностей работников, какие отражены в Справочнике, утверждены на основании функционирующего с 1.01.1996 Общероссийского классификатора, который содержит перечень профессий рабочих, должностей служащих и тарифных разрядов (ОКПДТР).
ЕКСД заключает в себе два раздела, каждый из которых посвящен характеристикам по квалификации для определенных должностей:
| Должности руководителей, специалистов и прочих служащих | В частности раздел касается наиболее широко распространенных профессий в производственных экономических отраслях. В том числе это относится и к бюджетным учреждениям |
| Должности работников, занятых в организациях научно-исследовательского характера | Конструкторских и подобных организациях, а также организациях редакционного и издательского типа |
Для квалификационной характеристики всякой должности предопределено три отдельных раздела:
| «Должностные обязанности» | Основополагающие рабочие функции, какие возможно вверить частично либо полностью сотруднику, занимающему описываемую должность с учетом взаимосвязи трудовых функций и технологической однородности, что дозволяет обеспечивать наилучшую специализацию в отношении служащих |
| «Должен знать» | Главные требования, которые предъявляют к работнику касательно специальных познаний. Здесь же установлены знания законов, нормативов, инструкций, положений, методик и прочих документов, какие работник обязан знать и которым ему надлежит следовать при осуществлении предусмотренных должностных обязанностей |
| «Требования к квалификации» | Обеспечивает выявление уровня касательно профессиональной готовности сотрудника, нужного для исполнения предопределенных должностных обязанностей. Также в этой части описаны требования к необходимому стажу. Уровни надлежащей профессиональной подготовки обусловлены положениями Закона РФ «Об образовании» |
В составе должностных характеристик предусмотрено также, что относительно одной и той же должности может применяться категорирование касательно оплаты труда без перемены названий должностей.
В Справочник не входят характеристики в отношении должностей старших и ведущих специалистов, заместителей руководящего состава подразделений.
Для таких работников трудовые обязанности, требования к познаниям и квалификационному уровню устанавливаются на основании прописанных в документе характеристик по схожим базовым должностям.
Действие в области ДОУ
В сфере ДОУ описание трудовых функций должностей и требования к работникам определяет «Единый квалификационный справочник должностей…», утвержденный на основе Приказа Минздравсоцразвития № 761н от 26.08.2010.
Непосредственно для области образования используется часть, касающаяся должностей сотрудников образования.
Он предуготовлен для разрешения вопросов, относящихся к урегулированию трудовых взаимоотношений, установления надлежащей эффективности при управлении работниками образовательных учреждений и организаций вне зависимости от форм собственности.
Раздел о квалификации должностей сотрудников образования заключает в себе четыре подраздела:
- Основные определения.
- Должности для руководящего состава.
- Должности для педагогического коллектива.
- Должности для учебно-вспомогательного персонала.
Установленные квалификационные требования используют в качестве нормативов.
Также их можно применять в качестве основания при составлении должностных инструкций, в каких установлен точный перечень по трудовым обязанностям сотрудников.
Причем инструкции составляются с учетом всех нюансов по организации трудовой деятельности и управления, надлежащей компетентности, ответственности и прав персонала.
По мере надобности должностные функции, отнесенные к квалификационной характеристике одной должности, иногда могут разделяться меж несколькими разными исполнителями.
Также могут утверждаться требования касательно требуемой спецподготовки сотрудников. Но в общих чертах должностная инструкция не должна противоречить ЕКС.
Для усовершенствования работы организации, а также для увеличения эффективности труда персонала учреждения допускается расширение круга трудовых обязанностей в сравнении с утвержденными квалификационными характеристиками для определенной должности.
В подобной ситуации без изменения наименования должности сотруднику может поручаться исполнение обязанностей, предопределенных квалификационными характеристиками для других должностей.
Основное условие в том, что работы должны быть близки по содержанию, равны по сложности, выполнение каких не требует другой квалификации или специальности.
Если работник помимо выполнения предусмотренных по должности обязанностей еще и руководит подчиненными ему работниками, то ему присваивается должностное наименование «старший».
Такое же звание может присваиваться работникам, осуществляющих функции руководства самостоятельным участком работы.
Таким образом, ЕКДС – это основной норматив, который призван решать вопросы относительно регулирования трудовых отношений.
Применение положений Справочника возможно для различных отраслей экономики, вне зависимости от организационно-правовых форм и видов деятельности по ОКВЭД. Посредством четких норм обеспечивается эффективность системы управления персоналом.
Видео: организация работы с молодежью
- В связи с частыми изменениями в законодательстве информация порой устаревает быстрее, чем мы успеваем ее обновлять на сайте.
- Все случаи очень индивидуальны и зависят от множества факторов. Базовая информация не гарантирует решение именно Ваших проблем.
Поэтому для вас круглосуточно работают БЕСПЛАТНЫЕ эксперты-консультанты!
- Задайте вопрос через форму (внизу), либо через онлайн-чат
- Позвоните на горячую линию:
ЗАЯВКИ И ЗВОНКИ ПРИНИМАЮТСЯ КРУГЛОСУТОЧНО и БЕЗ ВЫХОДНЫХ ДНЕЙ.
Квалификационный справочник должностей рабочих и служащих 2021
Статьи по теме
Квалификационный справочник должностей рабочих и служащих 2021 не один, их несколько. Мы познакомим вас с каждым. Кроме того, расскажем, какие существуют профстандарты, и как перейти на новую систему рабочих должностей.
Единый квалификационный справочник должностей рабочих и служащих 2021 создан для того, чтобы классифицировать существующие профессии. Кроме этого он позволяет описать служебные обязанности, выявить квалификацию работника, чтобы присвоить ему разряд или установить тариф. На его основе организации проводят аттестацию.
Единый квалификационный справочник должностей рабочих и служащих 2021
Единый квалификационный справочник – это условное название, так как на самом деле их два. Один посвящен рабочим специальностям (ЕКТС), другой служащим, руководителям и специалистам (ЕКС). Кроме того, в настоящее время предприятия все чаще пользуются профстандартами.
Для чего нужны все эти классификаторы. Без них ваш сотрудник не сможет получить профессиональные льготы, выйти раньше на пенсию, заработать дополнительные дни отдыха.
Поэтому вы вправе называть ту или иную специальность так, как вам нравится. Но если ее не будет в классификаторе, либо обязанности не совпадут, работник может лишиться многих социальных послаблений.
Кроме того, квалификационный справочник должностей рабочих и служащих 2021 потребуется:
- При присвоении разряда;
- При установлении оклада или тарифной ставки;
- Для проведения аттестации и переаттестации;
- Очертить должностные обязанности;
- Разобраться в целесообразности переквалификации и повышении квалификации.
Единый тарифно-квалификационный справочник работ и рабочих профессий
ЕКТС разработан Минтруда еще в 1992 году. Это громаднейший документ, состоящий из 72 выпусков. Выпуск – это своего рода отдел, объединяющий группу специальностей, которые разбиты по разделам.
Выпуск 10. В него входят два раздела: производство часов и технических камней, ремонт часов. Эти разделы включают в себя все должности, относящиеся к часовым механизмам: резьбонарезчик деталей часов, сборщик часов, шлифовщик камней и т.д. Список там внушительный.
Выпуск 23. Судостроение и судоремонт.
По такому же принципу строятся все остальные выпуски. Есть среди них такие, которые потеряли актуальность в наше время. Это 30-31, 38-39, 62-63, 65, 67-68.
Единый квалификационный справочник должностей руководителей, специалистов и служащих
ЕКС подписан Минтруда в 1998 году. Последнее обновление было в 2014 году. Редкость изменений объясняется тем, что в настоящее время более рационально пользоваться профстандартами, имеющими такое же назначение, но с более углубленной проработкой описаний специальностей.
В ЕКС содержится описание, список обязанностей требования к образованию должностей не рабочих специальностей. В справочнике 30 разделов. Описание специальностей собраны в 1 отделе. Прочие 29 содержат сведения по отдельным отраслям: здоровье, спорт и туризм, культура, оборона, охрана труда и пр.
Скачать его целиком можно выше. Важное отличие ЕКС от ЕКТС – это отсутствие в первом деления на разряды.
Почему же законодательство не обяжет работодателей полностью перейти на профстандарты. Это было бы удобнее и избавляло бы от необходимости пользоваться двумя классификаторами. Для этого есть несколько причин:
- Не все возможные профессии получили свои нормативы;
- Для перехода на стандраты для любой организации потребуется огромное количество времени;
- Не разработана всеобщая программа перехода.
Тем не менее, процесс идет. И ниже вы сможете познакомиться со схемой замены единого квалификационного справочника должностей рабочих и служащих на профстандарты.
Как заменить квалификационные справочники должностей рабочих и служащих на профстандрат
В 2021 году продолжится активный переход организаций со справочников ЕКТС и ЕКС на профстандарты. Ежегодно Минтруда утверждает новые стандарты той или иной профессии. В настоящий момент большинство ходовых специальностей имеют свое описание.
Например, есть штампы для педагога, программиста, соцработника, психолога, графического дизайнера, продавца оптики и т.д. Пересматриваются и рабочие должности: электромеханик по лифтам, горнорабочий, токарь и пр. Скачать перечень профстандартов можно выше.
Они будут выполнять ту же функцию, что и классификаторы, но предоставляют собой более точное описание должностей.
Пользоваться профнормами компаниям и ИП нужно тогда, когда:
- Какое-то рабочее место требует определенной квалификации и опыта, а данные по ним слишком расплывчаты в разных источниках;
- Если сотруднику, работающему по той или иной специальности будут положены льготы, послабления, дополнительные выплаты. Чтобы их обосновать, должность должна соответствовать профстандарту.
Переход на профессиональные нормативы длится не один день. Процесс может занять несколько месяцев. Однако Минтруда не представил какой-либо инструкции, регламентирующей всю эту сложную операцию. Мы можем предложить, делать переход по следующим этапам.
Этап 1. Разработать план-график внедрения профенормативов.
Этап 2. Создать рабочую комиссию из разных специалистов и представителей подразделений фирмы. Это делается путем издания приказа руководителем предприятия. В задачу комиссии входят следующие действия:
- Описание существующих должностей и проверка их соответствия существующим стандартам;
- Фиксация проверки, выявленных расхождений в отчетах и протоколах;
- Наброска тех параметров, которых не хватает для будущих инструкций
Этап 3. На основе существующих расхождений составление новых должностных инструкций. Иными словами, доведение существующих специальностей до нормативных параметров. Все новшества закрепляются приказом директора.
Помимо инструкций, нужно также определить какое образование, опыт работы потребуется для того или иного рабочего места.
Этап 4. Вероятнее всего после сверки выяснится, что организации требуется переквалификация отдельных кадров. Поэтому на этой ступени нужно будет утвердить систему обучения работников, источник финансирования переквалификации, что и как будет происходить.
Порядок переобучения зафиксируйте во внутренних документах.
Этап 5. На этой ступени принимается решение о проведении аттестации. Ее может и не быть. Все зависит от того, насколько разнились фактические служебные обязанности с указанными в профстандарте.
Если руководство принимает решение об аттестации сотрудников, все должно сопровождаться нормативным актом. В нем прописываются все нюансы: кто проводит аттестацию, ее форма, время проведения и пр.
Этап 6. Оформление бумаг по переходу на профстандарты. Вносятся корректирующие записи в части названия должностей. Параллельно делается правка в договорах с работниками, в трудовых книжках. Весь процесс сопровождается соответствующими приказами, распоряжениями, протоколами.
СледующаяДолжностные инструкцииСанитарка-мойщица: должностные обязанности
Отличная статья 0
Reddit Post Classification – KDnuggets
Эндрю Бергман, аналитик данных и специалист по решению проблем
Во время моего погружения в науку о данных третьим проектом, который мне пришлось выполнить, была классификация постов Reddit. Мы только что завершили очистку данных и обработку естественного языка, поэтому проект состоял из двух частей: очистить столько сообщений из API Reddit, сколько позволено, а затем использовать модели классификации для прогнозирования происхождения сообщений.
Я завершил проект некоторое время назад, но решил вернуться к нему с большим опытом: с тех пор я узнал о двух новых моделях классификации (поддерживающий векторный классификатор и классификатор XGBoost).
Сбор, очистка и предварительная обработка данных
Процесс извлечения данных из API Reddit довольно прост: это всего лишь базовый запрос, поскольку они не требуют ключа для доступа к API. К счастью для меня, у меня все еще был первый набор сообщений с того момента, когда я впервые завершил этот проект: всего у меня было около 4000 сообщений.
В некоторых отношениях очистка текста намного проще, чем очистка числовых данных: мне просто нужно было удалить нули, отфильтровать дубликаты и прикрепленные сообщения, отфильтровать перекрестные сообщения, небуквенные символы и URL-адреса.У меня было два источника текста в сообщениях: заголовок и самотекст (сам текст сообщения). Я решил объединить два источника в один документ, чтобы моделирование было немного проще. На этом этапе я решил взглянуть на самые частые слова из каждого сабреддита.
15 самых частых слов до лемматизации
Как только я понял, какие слова используются чаще всего, я смог добавить их в список используемых мной стоп-слов.
Последний шаг предварительной обработки, который я предпринял, – это лемматизация текста.Я выбрал лемматизацию вместо стемминга, потому что лемматизация – это более мягкий процесс, который стремится вернуть словарную форму слова, а не сокращать слово до его основы, что может возвращать не слова.
Моделирование
импорт НЛТК
импортировать панд как pd
импортировать numpy как np
импортировать seaborn как sns
импортировать matplotlib.pyplot как plt
из nltk.corpus импортировать стоп-слова
из нлтк.основной импорт WordNetLemmatizer
из nltk.tokenize import RegexpTokenizer
из sklearn.ensemble импортировать RandomForestClassifier
from sklearn.feature_extraction.text import TfidfVectorizerfrom
из sklearn.feature_extraction.text импорт CountVectorizer
из sklearn.linear_model import LogisticRegression
из sklearn.metrics импортировать confusion_matrix
из sklearn.metrics import roc_auc_score
из склеарна.импорт показателей precision_score, f1_score
из sklearn.metrics импортировать balance_accuracy_score
из sklearn.model_selection import GridSearchCV
из sklearn.model_selection import train_test_split
из skearnn.model_selection импорт cross_val_score
из sklearn.pipeline import Pipeline
из sklearn.svm импортировать SVC
из sklearn.tree импортировать DecisionTreeClassifier
из xgboost импортировать XGBClassifier
Я подошел к проблеме с 4 моделями: логистическая регрессия, классификатор опорных векторов (SVC) и классификатор XGBoost.Каждая модель запускалась дважды: один раз с векторизатором подсчета и один раз с векторизатором TFIDF (термин «частота-обратная частота документа»).
- Векторизатор счетчика берет каждое слово из каждой строки данных, создает для него столбец и подсчитывает, сколько раз встречается это слово.
- Векторизатор TFIDF делает то же самое, но вместо того, чтобы возвращать счетчик, возвращает частоту в процентах, масштабированных по тому, как часто она появляется во всех документах.
Мне пришлось использовать gridsearch для каждой модели, потому что я настраивал 2 набора гиперпараметров (параметры, которые алгоритм не может определить): один набор для векторизаторов и один набор для реальных моделей.
Когда дело дошло до оценки, я использовал три набора показателей: оценки показателей (точность, оценка F1 и т. Д.), Матрицы неточностей и кривую ROC (рабочие характеристики приемника). Для простоты я покажу оценки только для лучшей модели, иначе изображений будет слишком много.
Я начал с модели логистической регрессии, потому что она проста: если эта модель работает плохо, мне придется перейти к другому типу модели. Производительность логистической регрессии была разной: она работала намного лучше с векторизатором TFIDF и была переоборудована.
Следующей моделью, которую я попробовал, была модель SVC. Я думал, что, поскольку алгоритм вектора поддержки использует трюк с ядром для перемещения данных в более высокие измерения, он лучше справится с разделением классов. Однако он не превзошел логистическую регрессию, что меня очень удивило. Результаты SVC с обоими векторизаторами практически не переборщили, что также было неожиданностью.
Затем я перешел к классификатору случайного леса. Поскольку векторизатор может генерировать сотни функций, я подумал, что случайный выбор функций, встроенный в алгоритм случайного леса, будет устранять дисперсию лучше, чем в предыдущих моделях.Случайный лес работал лучше, чем SVC, но все равно был хуже, чем логистическая регрессия.
Наконец, я обратился к XGBoost. Классификатор XGBoost – это классификатор на основе дерева, который реализует повышение (подгонку моделей к предыдущим ошибкам) и градиентный спуск. Я был уверен, что это будет моя лучшая модель, но это не так: она все равно превзошла SVC и random forest
.Лучшая модель
Моей лучшей моделью была логистическая регрессия с векторизацией TFIDF.Несмотря на то, что это лучшая модель, это далеко не хорошая модель.
Пять метрических баллов
Я выбрал эти метрики, потому что они по-разному представляют точность модели.
- Точность – это общее количество правильных прогнозов.
- Точность балансировки – это среднее значение чувствительности для обоих классов
- Специфичность – сколько отрицательных прогнозов верны (r / AskCulinary)
- Чувствительность – сколько положительных прогнозов верны (r / Cooking)
- F1 Score – это среднее гармоническое значение специфичности и чувствительности, а также еще одно измерение точности.
Эта модель превзошла базовую линию (черная линия) с точки зрения точности и сбалансированной точности, но ее оценки все еще невысоки. Я оптимизировал для чувствительности, что означает, что я хотел предсказать сообщения от r / Cooking, но эта модель имела ужасную чувствительность: она лучше предсказывала отрицательный класс (r / AskCulinary), потому что было больше экземпляров этого. Оценка F1 низкая из-за низкой чувствительности.
Кривая ROC с AUC 0,66419
Кривая ROC отображает способность логистической регрессии различать два класса, т.е.е. r / Cooking & r / AskCulinary. Сама кривая показывает соотношение между чувствительностью и ложными срабатываниями. Однако более важным является AUC (площадь под кривой), потому что он показывает различие между обоими классами. Наименьшая возможная оценка – 0,5, а моя лучшая модель – 0,66, что совсем не очень хорошо: модели трудно различать классы.
Выводы
Мне не удалось должным образом классифицировать исходный субреддит для сообщений, с которыми я работал.
Характеристики модели оставляли желать лучшего. У других моделей были показатели специфичности, но с остальными они были хуже. Кроме того, модели были переобучены, хотя я пробовал алгоритмы, которые могут помочь справиться с переобучением.
Метод векторизации улучшил производительность, но не сильно; это область, в которой я хотел бы продолжить эксперименты.
Наконец, я хотел бы попробовать запустить нейронную сеть, потому что они очень хорошо справляются с задачами классификации.
Мне не удалось получить желаемых результатов, но это нормально: не все получается так, как вы хотите, в реальном мире.
Репозиторий проекта можно найти здесь.
Со мной также можно связаться через LinkedIn.
Биография: Эндрю Бергман стремится использовать данные для решения реальных проблем на благо людей. Его опыт работы с образовательными данными показал ему важность рассмотрения человеческой стороны данных. Он использует свои навыки критического мышления вместе со своим любопытством и дотошностью, чтобы предложить сторонний подход к решению проблем.
Оригинал. Размещено с разрешения.
Связанный:
(PDF) Классификация сообщений в социальных сетях, связанных со здоровьем: анализ и оценка (препринт)
Социальные сети, связанные со здоровьем. Mislove et al [17] оценили пол и этническую принадлежность пользователей Твиттера
, используя первые
имени и фамилии. Сада и др. [12] расширили работу
Mislove и др. [17], рассматривая псевдонимы при оценке пола
.В этом исследовании мы использовали методы классификации текста, чтобы
идентифицировать категории контента публикаций в социальных сетях, связанных со здоровьем
, и использовали методы, предложенные в исследованиях Sadah et al.
[12] и Mislove et al [17], чтобы изучить частоту этих
категорий в нескольких демографических группах.
Методы
Наборы данных
Для онлайн-форумов, связанных со здоровьем, мы выбрали 2 разных веб-сайта
, WebMD и DailyStrength.Причина выбора
2 онлайн-форумов, связанных со здоровьем, заключается в том, чтобы охватить различные типы
онлайн-форумов, связанных со здоровьем, которые каждый из них представляет. Хотя
WebMD состоит из нескольких сообществ здоровья, где люди
задают вопросы и получают ответы от членов сообщества
[18], DailyStrength позволяет пациентам обмениваться опытом
и лечения, обсуждать повседневные проблемы и успехи, а
получают эмоциональные ответы. поддержка [19].Для каждого сообщения, полученного с
этих веб-сайтов, мы извлекли URL-адрес, заголовок, имя пользователя, время публикации
, текст сообщения и название доски сообщений
. Для каждого пользователя собранного сообщения мы также собрали
возраста автора, друзей, пола и местоположения, где это применимо.
Поскольку сканирование этих сайтов выполнялось в разное время,
некоторые из собранных нами данных не отражают текущую доступность
определенных атрибутов из-за изменения формата веб-сайта
, например, возраст и пол в настоящее время доступно
из профилей пользователей WebMD, но раньше не было.В этом исследовании
выбор демографических атрибутов, которые мы использовали для
источника, основан на доступности, отраженной большинством
сообщений, собранных из этого источника, например, большинство из
сообщений WebMD в наших данных были собраны до того, как были доступны возраст и пол
, поэтому мы не использовали эти атрибуты для анализа демографических данных пользователей WebMD
. Мы ограничили использование сообщений
из этих источников первым сообщением в каждой ветке.В нашем анализе
мы использовали тело сообщения, заголовок сообщения, имя доски сообщений,
и имя пользователя из WebMD, а также тело сообщения, заголовок сообщения, имя доски сообщений
, а также пол, возраст и местоположение пользователя из
. DailyStrength.
Для обычных социальных сетей мы выбрали Twitter и Google+, так как
они предлагают интерфейсы для простого сбора данных (в отличие от
Facebook). Для каждого сообщения Twitter мы собрали содержание сообщения, время публикации
, местонахождение, а также имя пользователя и местонахождение автора.Для
каждого сообщения Google+ мы собрали заголовок, время публикации, время обновления,
– содержание сообщения, местоположение и имя пользователя автора, первые
и фамилию, возраст, пол и местоположение. Поскольку Twitter и
Google+ являются общими социальными сетями, мы использовали 274 репрезентативных
ключевых слов, связанных со здоровьем, чтобы отфильтровать их следующим образом: (1) Лекарства:
из большинства рецептов, выписанных из RxList [20], мы выбрали
200 самых популярных препаратов.После удаления вариантов
одного и того же лекарства (например, с разными дозировками в миллиграммах) окончательный список
лекарств содержал 124 уникальных названия лекарств. (2) Хэштеги: 11
популярных хэштегов Twitter, связанных со здоровьем, например #BCSM (Breast
Cancer and Social Media). (3) Заболевания: 81 часто обсуждаемых
расстройств, таких как СПИД и астма. (4)
Pharmaceuticals: названия 12 крупнейших фармацевтических компаний
, таких как Novartis.(5) Страхование: названия
44 крупнейших страховых компаний, таких как Aetna и Shield. (6)
Общие связанные со здоровьем ключевые слова «здравоохранение» и «здравоохранение
страхование». Чтобы достичь окончательного подсчета ключевых слов для хэштегов,
расстройств, фармацевтических препаратов и страхования, мы выбрали каждое ключевое слово
из большего списка для каждой из этих категорий и сохранили
ключевых слов с высоким соотношением сообщений, связанных со здоровьем. В нашем анализе
мы использовали тело твита, имя и фамилию пользователя и местоположение пользователя
из Twitter, а также тело сообщения, заголовок сообщения и пол, возраст, имя и фамилию пользователя, а также местонахождение из Google+.
Чтобы отфильтровать Twitter с помощью списка ключевых слов, связанных со здоровьем, чтобы получить
релевантных твитов для TwitterHealth, мы использовали потоковый интерфейс Twitter
прикладного программирования (API) [21]. Точно так же мы
использовали Google+ API [22] для извлечения соответствующих сообщений для
Google + Health. Для онлайн-форумов, посвященных здоровью, WebMD и
DailyStrength, мы создали сканер для каждого веб-сайта на Java, используя
jsoup [23], библиотеку для извлечения и анализа содержимого HTML.Таблица
1 перечисляет для каждого источника количество собранных сообщений, дату
диапазонов собранных сообщений и то, присутствуют ли демографические атрибуты
, используемые в этом исследовании, а таблица 2 перечисляет распределение демографических данных
для каждого источника по каждый
демографический признак. Для всех 4 этих источников мы не делали
специально для нашего поиска англоязычных постов, кроме
с использованием английских названий наркотиков; однако большинство сообщений
, собранных из этих источников, были на английском языке.
Таблица 1. Список всех использованных источников с указанием количества сообщений, диапазона дат публикации и доступных демографических атрибутов.
Местоположение Этническая принадлежность Возраст Пол Диапазон дат Количество сообщений Источник
Yesb
Классификатор этнической принадлежности
[17]
Noa
Половой классификатор
[17]
2 мая 2013 г. по
000 г.Да Классификатор этнической принадлежности
[17]
Да Да 24 августа 2009 г. – 5 января
2014 г.
186 666 Google + Здоровье [25]
Да Нет Да Да ]
NoNoNoGender classifier
[12]
24 декабря 2006 г. по 11 мая
2019
318,297WebMD [27]
a Демографический атрибут не предоставляется источником и не используется классификатор из-за низкой точности .
bДемографический атрибут предоставлен источником.
Обзор общественного здравоохранения JMIR, 2020 | т. 6 | выпуск 2 | e14952 | п. 3 https://publichealth.jmir.org/2020/2/e14952 (номер страницы не для цитирования)
Rivas et al. JMIR ОБЩЕСТВЕННОЕ ЗДОРОВЬЕ И НАДЗОР
XSL
•
FO
RenderX
Обработка естественного языка и машинное обучение | автор: BrittКак вы уже догадались, мне было поручено использовать машинное обучение, чтобы сделать то, что вы только что пытались сделать выше! Другими словами, создает модель классификации, которая может различать, какому из двух субреддитов сообщение принадлежит .
Предположение для этой проблемы состоит в том, что недовольный разработчик серверной части Reddit просматривал все сообщения и заменял поле subreddit на «(· ̿̿Ĺ̯̿̿ · ̿ ̿)». В результате ни одна из ссылок сабреддита не будет заполнена сообщениями до тех пор, пока поля сабреддита каждой публикации не будут переназначены.
Как вы, возможно, уже догадались, посты в r / BabyBumps и r / menstruation определенно будут иметь много общего. Например, представьте, что женщины говорят о пристрастии к еде, судорогах или перепадах настроения в любом из каналов.Мне нравятся задачи, поэтому я специально выбрал два тесно связанных субреддита, поскольку хотел увидеть, насколько хорошо я могу использовать обработку естественного языка и машинное обучение, чтобы точно переклассифицировать сообщения в соответствующие субреддиты.
* Ответ на ледокол можно найти в последнем предложении следующего раздела, но продолжайте читать, чтобы увидеть, умнее ли вы, чем алгоритм, который я построил!
Мой процесс сбора данных включал использование библиотеки запросов для циклического прохождения запросов на получение данных с использованием API Reddit, что довольно просто.Чтобы получать сообщения из / r / menstruation, все, что мне нужно было сделать, это добавить .json в конец URL-адреса. Reddit предоставляет только 25 сообщений на запрос, а я хотел 1000, поэтому я повторил процесс 40 раз. Я также использовал функцию time.sleep () в конце цикла, чтобы сделать перерыв в одну секунду между запросами.
Мой цикл for вывел список вложенных словарей json, из которых я проиндексировал желаемые функции, Post Text и Title , одновременно добавив их в два фрейма Pandas DataFrames, один для сообщений, связанных с r / BabyBumps, и другое для постов, связанных с г / менструацией.
После получения моих сообщений в соответствующих DataFrames я проверил наличие повторяющихся и нулевых значений, оба из которых имели место. Для повторяющихся значений я избавился от них с помощью функции drop_duplicates () . Нулевые значения встречаются только в моем столбце Post Text , это происходит, когда пользователь Reddit решает использовать только поле заголовка. Я решил не отбрасывать нулевые значения, поскольку я не хотел терять ценную информацию в сопровождающих строках моего подвига Title , поэтому вместо этого я заполнил пустые значения уникальным и произвольным текстом.
После очистки и объединения моих данных мой последний DataFrame содержал 1818 документов (строк) и 3 функции (столбцы). Третьей особенностью была моя цель, у которой был баланс классов 54% для класса 1 (r / BabyBumps) и 46% для класса 0 (r / менструация) – ответ ледокола !
Я создал облако слов, потому что это весело, и мы работаем с текстовыми данными!
Это облако слов содержит 100 слов из обоих подреддитов. Я создал его, чтобы получить визуальное представление о частотах (более крупные / жирные слова имеют более высокую частоту) слов и о том, как их общность в субреддитах может испортить мою модель; или как это может сработать в пользу моей модели, если это слово / фраза вроде «менструальная чаша» имеет среднюю частоту и, вероятно, появляется или чаще всего появляется в сообщениях о менструации.
Я начал процесс моделирования с создания моих X и моих y и разделения моих данных на обучающие и тестовые наборы. Затем я перешел к процессу разработки функций, создав два экземпляра CountVectorizer для моих функций Post Text и Title . CountVectorizer преобразует коллекцию текстовых документов (строки текстовых данных) в матрицу счетчиков токенов. Я пропустил через них следующие гиперпараметры (аргументы):
- stop_words = ‘english’ ( Post Text & Title )
- strip_accents = ‘ascii’ ( Post Text & Title )
- ngram_range = (1, 6), min_df =.03 ( Post Text )
- ngram_range = (1, 3), min_df = .01 ( Title )
Стоп-слова удаляют слова, которые обычно встречаются в английском языке. Полосовые акценты удаляют акценты и выполняют другую нормализацию символов. Min_df игнорирует термины, частота которых в документе строго ниже заданного порогового значения.
N-грамма – это просто строка из n слов подряд. Например, если у вас есть текстовый документ, содержащий слова «Я люблю свою кошку». – установка диапазона n-граммов на (1, 2) даст: «Я люблю | люблю мой | моя кошка”.Наличие н-граммовых диапазонов может быть полезно для предоставления моделям большего контекста вокруг текста, который я им скармливаю.
Я предположил, что установка функции Title с диапазоном n-грамм (1, 4) убирает шум и будет более полезной для моей модели, добавив больше контекста, чем если бы ее просто оставили в покое. Я все еще устанавливаю нежный min_df, чтобы убрать любой дополнительный шум. Я сделал аналогичные предположения для моей функции Post Text , хотя я дал ей более высокий диапазон n-граммов, поскольку тексты сообщений имеют тенденцию быть более длинными.
В результате получилось 393 функции, которые я добавил в две разновидности моделей, перечисленных ниже. Я построил четыре функции для запуска каждой пары моделей и провел поиск по сетке по нескольким гиперпараметрам, чтобы найти лучшие из них, подходящие для моей окончательной модели.
Разница в вариациях составила штраф и параметры решателя . Решатели newton-cg, lbfgs и sag обрабатывают только штраф L2 (регуляризация гребня), тогда как liblinear и saga обрабатывают L1 (регуляризация лассо).
- Деревья решений и случайные леса
Разница в вариациях для этих двух моделей составляла критерий параметра . Один был установлен на «Джини» (примесь Джини), а другой – на «энтропию» (получение информации).
Разница в вариациях заключалась в аргументе fit_prior , который решает, следует ли изучать априорные вероятности класса или нет. Если false, будет использоваться униформа приора. Один был установлен на True, а другой – на False.
Моя вторая полиномиальная наивная байесовская модель показала лучшие результаты. С лучшими параметрами – alpha = 0 и fit_prior = False. Оценка точности составила 92,4% для обучающих данных и 92,2% для невидимых данных. Это означает, что наша модель немного и, вероятно, несущественно переобучена. Это также означает, что 92,2% наших сообщений будут точно классифицированы нашей моделью.
Учитывая небольшой объем собранных данных и минимальное количество используемых функций, полиномиальная наивная байесовская модель была самой выдающейся.Он хорошо обрабатывал невидимые данные и уравновешивал компромисс между смещением и дисперсией, лучший среди восьми моделей, поэтому я бы использовал его для переклассификации сообщений Reddit.
Однако, если у вас будет больше времени и данных для ответа на проблему, я бы порекомендовал две вещи: 1) уделять больше времени текущим функциям (например, разработка функции длины слова) и 2) изучать новые функции (например, голосовать за или публиковать комментарии).
Выявление и классификация экстремистской принадлежности в социальных сетях с использованием методов анализа настроений | Информатика и информатика, ориентированные на человека
Сбор данных
Мы использовали API потоковой передачи Twitter [26] для удаления твитов, содержащих одно или несколько связанных с экстремизмом ключевых слов (ИГИЛ, бомба, самоубийство и т. Д.)). Кроме того, мы также исследовали различные форумы Dark Web, такие как Al-Firdaws, Montada, alokab и Islamic Network [27]. Первые три – это арабские форумы, а третий – на английском. Мы собрали более 25 000 сообщений, переведя сообщения с других языков на английский с помощью API-интерфейса Google Translate на основе Python (https://pypi.org/project/googletrans/). Каждый обзор сопоставляется с исходными словами, присутствующими в составленной вручную лексике экстремистов, полученной от BiSAL [28], двуязычной лексики настроений для анализа форумов дарквеба.Таким образом, собираются все сообщения, содержащие одно или несколько ключевых слов из словаря, полученного вручную. Для этого мы использовали скрипт beautiful-soupscript на основе Python (https://codeburst.io/web-scraping-101-with-python-beautiful-soup-bb617be1f486).
Полученные данные сохраняются в машиночитаемом файле «.CSV». Таким образом, мы получили вручную помеченные наборы обучающих данных для проведения экспериментов. Набор обучающих данных состоит из 12 754 твитов, помеченных как « экстремистских » и 8432 как « не – экстремистских » [29].Таблица 1 показывает детали использованного набора данных. В таблице 2 показан примерный список часто встречающихся терминов в наборе данных, показывающий частоту терминов (tf), частоту документов (df) и частоту пользователей (uf).
Таблица 1 Статистика набора данных Таблица 2 25 самых часто встречающихся терминовПредварительная обработка
Мы применили различные методы предварительной обработки, такие как токенизация, удаление стоп-слова, преобразование регистра и удаление специальных символов [30]. Токенизация дает набор уникальных токенов (356 242), которые помогают в создании словаря из обучающего набора, используемого для кодирования текста.
Обучение, проверка и тестирование
Мы разделили набор данных на три части: обучение, проверка и тестирование. Модель DL обучается с помощью библиотеки Keras [31] на основе TensorFlow. Аппаратные требования включают 4 GPU Titan X, 128 ГБ памяти с узлом Intel Core i7. На рисунке 1 показано схематическое представление разделения поездов, проверки и тестирования.
Рис. 1Обучение, проверка и разделение тестов
Данные обучения
Данные обучения используются для обучения модели.В этой работе 80% данных используется для обучения и может варьироваться в зависимости от требований эксперимента. Данные обучения включают в себя как входные, так и ожидаемые выходные данные. Он включает как вход, так и соответствующий ожидаемый результат [32].
В таблице 3 показан примерный список предложений для обзора в обучающих данных.
Таблица 3 Частичный список обучающих данныхПроверка данных
Проверка данных используется для минимизации переобучения и неполной подгонки [33], что обычно происходит из-за высокой точности фазы обучения и снижения производительности по сравнению с тестом. данные.Поэтому используется 10% набор проверок, чтобы избежать ошибок производительности путем настройки параметров. Для этой цели мы применили автоматическую проверку набора данных [34], которая обеспечивает объективную оценку модели и минимизирует переобучение [35].
Тестовые данные
Тестовые данные (20%) используются для проверки того, хорошо ли обученная модель работает с невидимыми данными. Он используется для окончательной оценки модели, когда она полностью обучена. Список образцов записей в тестовых данных представлен в таблице 4.
Таблица 4 Частичный список тестовых данныхПредлагаемая сетевая модель
Предлагаемый метод реализует и оценивает производительность долговременной краткосрочной памяти с моделью сверточной нейронной сети (CNN) для идентификации твитов / обзоров, содержащих контент с экстремистскими зацепками. Мы обучаем нейронный классификатор для классификации содержания экстремистской принадлежности. Рабочий процесс сети состоит из следующих шагов: (i) встраивание слов, при котором каждому слову в предложении присваивается уникальный индекс для формирования вектора фиксированной длины, (ii) слой исключения используется, чтобы избежать переобучения, ( iii) слой LSTM включен для захвата зависимости между твитами / обзорами на большом расстоянии (iii) извлечение признаков выполняется с помощью операции свертки, (iv) уровень объединения нацелен на минимизацию размера карты признаков путем агрегирования информации, (v) сглаживание Layer преобразует объединенную карту объектов в вектор-столбец, и (vi) на выходном слое для классификации используется функция softmax.На рисунке 2 представлена сетевая диаграмма для классификации приговора как «экстремистский» или «не – экстремистский контент». В оставшейся части этой статьи мы подробно описываем работу с этими слоями.
Рис. 2Архитектура LSTM + CNN для классификации экстремистской принадлежности
Слой встраивания слов (входной)
Встраиваемый или входной уровень – это первый уровень модели LSTM + CNN, который преобразует слова в векторное представление с действительным знаком, т. Е. Создается словарь слов, который затем преобразуется в числовая форма, известная как встраивание слов.Вложение слова дается в качестве входных данных (матрица предложений) для следующего уровня. Как показано в псевдокоде, существуют разные параметры, а именно (i) максимальное количество функций, (ii) встроенное тусклое изображение и (iii) длина ввода. « max_features» содержит самые популярные слова и представляет размер словарного запаса; « embed_dim» показывает размерность вектора с действительным знаком, а « input_length» описывает длину каждой входной последовательности.
Предложение состоит из последовательности слов: x 1 , x 2 … x n , и каждому слову присваивается эксклюзивный порядковый номер.Слой внедрения преобразует такие индексы в D-мерный вектор слов. Для этой цели матрица внедрения размером [ размер словаря × размер внедрения ]) изучается по матрице размером 10 × 4, то есть ([V × D] = [10 × 4]). Так как в этом случае размер словаря равен 10, а размер встраивания равен 4, поэтому отдельное слово « Baghdadi » представлено как 1 4-мерным вектором, то есть (1 × D = [1 × 4]. Например, , слово « Baghdadi » с индексом «1» содержит вектор вложения [0.2, 0,4, 0,1, 0,2], представленной первой строкой, показанной на рис. 3. Точно так же вторая строка – [0,6, 0,2, 0,8, 0,8], и то же самое для других. Таким образом, мы можем ясно видеть, что каждое слово имеет вложение размером «1 × D», как показано на рис. 3. Матрица вложения обозначается как E ϵ R V × D . Процесс встраивания слов проиллюстрирован следующим образом:
Рис. 3Представление слова во входном слое
Слой исключения
Функция слоя исключения состоит в том, чтобы избежать переобучения.Значение 0,5 представляет параметр « rate» слоя отсева, а значение этого параметра находится между 0 и 1 [36]. Слой исключения случайным образом удаляет или отключает активацию нейронов в слое внедрения, когда исключение применяется к слою внедрения, тогда как каждый нейрон в слое внедрения отображает плотное представление слова в предложении. Моделирование выпадения на одном нейроне представлено в формуле. (1):
$$ f (k, p) = \ left \ {{\ begin {array} {ll} p & \ quad {if \ k = 1} \\ {1 – p} & \ quad { если \ k = 0} \\ \ end {array}} \ right.$
(1)
k отображает желаемые результаты, а p – вероятность, связанная с представлением слов с действительными значениями. Таким образом, когда значение p равно 1, нейрон, содержащий реальное значение, будет удален и активируется в противном случае. На рисунке 4 показана работа выпадающего слоя.
Рис. 4Работа слоя исключения
На рисунке 4 показан слой внедрения, который содержит действительное представление данного предложения: Багдади… наша последняя и единственная надежда, я просто люблю тебя., поэтому после добавления слоя исключения некоторые значения в слое внедрения деактивируются случайным образом (рис. 4).
Долговременная краткосрочная память
Мы использовали один слой LSTM, который состоит из 100 ячеек / единиц lstm. LSTM выполняет некоторые предварительные вычисления перед выходом. В каждой ячейке выполняется четыре независимых вычисления с использованием четырех вентилей: забыть (ft), вход (it), кандидат (c ~ t) и выход (ot). Уравнения для этих ворот приведены ниже [37]:
$$ ft = \ sigma \ left ({Wfxt + Uf ht – 1 + bf} \ right) $$
(2)
$$ it = \ sigma \ left ({Wixt + Ui ht – 1 + bi} \ right) $$
(3)
$$ Ot = \ sigma \ left ({Wo xt + Uo ht – 1 + bo} \ right) $$
(4)
$$ C \ sim t = \ tau \ left ({Wc xt + Uc ht – 1 + bc} \ right) $$
(5)
$$ Ct = ft oCt – 1 + it oC \ sim t $$
(6)
$$ ht = Ot o \ tau \ left ({Ct} \ right) $$
(7)
Графическое изображение всей ячейки LSTM в зеленом блоке показано на рис.5.
Рис. 5Ячейка долговременной краткосрочной памяти
Теперь примерное предложение: « Багдади… наша последняя и единственная надежда, я просто люблю тебя» передается через ячейку LSTM. Выполнение сначала начинается с ворот забыть, используя уравнение. (2) в котором вход x t и предыдущий выход h t умножаются на их соответствующие веса Wf, Uf . Следующее смещение добавляется bf , которое выводит вектор (4 × 1). Затем применяется сигмовидная функция активации для преобразования значений от 0 до 1 в значения больше 0.5 принимается равным 1 для трех ворот ft, it, Ot, как показано в расчетах ниже [38]. Затем для входного и выходного вентиля повторяется та же процедура, а для элемента-кандидата вместо сигмоида используется функция касательной. Наконец, выходные h t и векторы следующего состояния c t ячейки вычисляются с использованием формул. (6) и (7).
Ввод значений в уравнения. (2), (3), (4), (5), (6), (7)
$$ {\ text {f}} _ {\ text {t}} = \ sigma \ left ({\ left [{\ begin {array} {* {20} c} {0.1} & {0.3} & {0,2} & {0,4} \\ {0,2} & {0,1} & {0,5} & {0,3} \\ {0,3} & {0,6} & {0,3} & {0,2} \\ {0,1} & {0.2} & {0.5} & {0.3} \\ \ end {array}} \ right] \ times \ left [{\ begin {array} {* {20} c} {0.2} \\ {0.4} \\ {0,1} \\ {0,2} \\ \ end {массив}} \ right] + \ left [{\ begin {array} {* {20} c} {0,1} & {0,2} & {0,5} & {0,6 } \\ {0,3} & {0,4} & {0,1} & {0,7} \\ {0,2} & {0,3} & {0,5} & {0,4} \\ {0,4} & {0,1} & {0,3} & { 0,2} \\ \ end {array}} \ right] \ times \ left [{\ begin {array} {* {20} c} 0 \\ 0 \\ 0 \\ 0 \\ \ end {array}} \ справа] + \ left [{\ begin {array} {* {20} c} {0.1} \\ {0.2} \\ {0.3} \\ {0.4} \\ \ end {array}} \ right]} \ right) = \ left [{\ begin {array} {* {20} c} 1 & 1 & 1 & 1 \\ \ end {array}} \ right] $$
$$ {\ text {i}} _ {\ text {t}} = \ sigma \ left ({\ left [{\ begin {array} {* {20} c} {0.4} & {0.3} & { 0,1} и {0,5} \\ {0,2} и {0,6} и {0,4} и {0,1} \\ {0,3} и {0,5} и {0,6} и {0,7} \\ {0,2} и {0,1} и {0,4} & {0,3} \\ \ end {array}} \ right] \ times \ left [{\ begin {array} {* {20} c} {0,2} \\ {0,4} \\ {0,1} \ \ {0.2} \\ \ end {array}} \ right] + \ left [{\ begin {array} {* {20} c} {0,5} & {0,1} & {0,4} & {0,6} \\ {0,4} & {0,3} & {0,2} & {0,7} \\ {0,6} & {0,2} & {0,4} & {0,8} \\ {0,2} & {0,7} & {0,8} & {0,1} \\ \ end {массив}} \ right] \ times \ left [{\ begin {array} {* {20} c} 0 \\ 0 \\ 0 \\ 0 \\ \ end {array}} \ right] + \ left [ {\ begin {array} {* {20} c} {0.1} \\ {0.3} \\ {0.4} \\ {0.2} \\ \ end {array}} \ right]} \ right) = \ left [ {\ begin {array} {* {20} c} 1 & 1 & 1 & 1 \\ \ end {array}} \ right] $$
$$ {\ text {c}} \ sim {\ text {t}} = \ tau \ left ({\ left [{\ begin {array} {* {20} c} {0.3} & {0,2} & {0,5} & {0,6} \\ {0,1} & {0,3} & {0,4} & {0,2} \\ {0,5} & {0,6} & {0,7} & {0,1} \\ {0,4} & {0,3} & {0,2} & {0,7} \\ \ end {array}} \ right] \ times \ left [{\ begin {array} {* {20} c} {0,2} \\ { 0,4} \\ {0,1} \\ {0,2} \\ \ end {array}} \ right] + \ left [{\ begin {array} {* {20} c} {0,5} & {0,1} & {0,4 } & {0,6} \\ {0,4} & {0,3} & {0,2} & {0,7} \\ {0,6} & {0,2} & {0,4} & {0,8} \\ {0,2} & {0,7} & { 0,8} & {0,1} \\ \ end {array}} \ right] \ times \ left [{\ begin {array} {* {20} c} 0 \\ 0 \\ 0 \\ 0 \\ \ end { массив}} \ right] + \ left [{\ begin {array} {* {20} c} {0.4} \\ {0.1} \\ {0.2} \\ {0.3} \\ \ end {array}} \ right]} \ right) = \ left [{\ begin {array} {* {20} c} { 0,6} & {0,3} & {0,5} & {0,5} \\ \ end {array}} \ right] \, $$
$$ {\ text {o}} _ {t} = \ sigma \ left ({\ left [{\ begin {array} {* {20} c} {0.2} & {0.1} & {0.5} & { 0,6} \\ {0,3} и {0,4} и {0,2} и {0,1} \\ {0,1} и {0,5} и {0,6} и {0,7} \\ {0,6} и {0,4} и {0,3} и {0.2} \\ \ end {array}} \ right] \ times \ left [{\ begin {array} {* {20} c} {0.2} \\ {0.4} \\ {0.1} \\ {0,2} \\ \ end {массив}} \ right] + \ left [{\ begin {array} {* {20} c} {0,1} & {0,2} & {0,5} & {0,3} \\ {0,6} и {0,3} и {0,2} и {0,4} \\ {0,7} и {0,4} и {0,1} и {0,8} \\ {0,8} и {0,5} и {0,2} и {0,3 } \\ \ end {array}} \ right] \ times \ left [{\ begin {array} {* {20} c} 0 \\ 0 \\ 0 \\ 0 \\ \ end {array}} \ right ] + \ left [{\ begin {array} {* {20} c} {0,7} \\ {0,6} \\ {0,5} \\ {0,4} \\ \ end {array}} \ right]} \ right ) = \ left [{\ begin {array} {* {20} c} 1 & 1 & 1 & 1 \\ \ end {array}} \ right] $$
$$ {\ text {c}} _ {\ text {t}} = \ left [{\ begin {array} {* {20} c} 1 & 1 & 1 & 1 \\ \ end {array}} \ right] \ cdot \ left [{\ begin {array} {* {20} c} 0 & 0 & 0 & 0 \\ \ end {array}} \ right] + \ left [{\ begin {array} { * {20} c} 1 & 1 & 1 & 1 \\ \ end {array}} \ right] \ cdot \ left [{\ begin {array} {* {20} c} {0.6} & {0,3} & {0,5} & {0,5} \\ \ end {array}} \ right] $$
$$ {\ text {h}} _ {\ text {t}} = \ left [{\ begin {array} {* {20} c} 1 & 1 & 1 & 1 \\ \ end {array}} \ right] \ cdot \ tau \ left [{\ begin {array} {* {20} c} {0,6} & {0,3} & {0,5} & {0,5} \\ \ end {array}} \ right] = \ left [{\ begin {array} {* {20} c} {0.5} & {0.2} & {0.4} & {0.} \\ \ end {array} 4} \ right] $$
Отсюда мы передаем наши h t и c t , чтобы начать вычисления следующей ячейки lstm.{lxw} \). Наконец, это представление подается на уровень CNN.
Сверточный слой
На этом уровне выполняется сверточная операция, которая представляет собой математическую операцию, реализованную над двумя функциями, в результате чего получается третья функция. Для выполнения сверточной операции размеры входной матрицы (P), матрицы фильтра (F) и выходной матрицы (T) представлены следующим образом:
В формуле. (8), P представляет входную матрицу, созданную слоем LSTM, R обозначает все действительные числа, l – длину и w – ширину входной матрицы, которая отображается как R 10 × 4 .
В формуле. (9), F представляет матрицу фильтра, R обозначает все действительные числа, n – длина и м – ширина матрицы фильтра, которая отображается как R 2 × 2 и
В формуле. (10), T представляет матрицу вывода, R обозначает все действительные числа, s – длину и d – ширину выходной матрицы, которая отображается как R 10 × 4 .{m} f_ {l, w} \ время p_ {i + l – 1, j + w – 1} $$
(11)
где, t i, j ϵ R s × d – t -й элемент выходной матрицы, f l, w 905 R n × n представляет f -й элемент весовой матрицы, ⊗ обозначает поэлементное перекрестное умножение и p i + l – 1, j + w – 1 ϵ R l × w представляет p -е элементы входной матрицы.
Для примера предложения: « Багдади… наша последняя и единственная надежда, я просто люблю тебя» , сверточная операция выполняется следующим образом: (i) Элементы входной матрицы 0,5, 0,2, 0,2, 0,7, ( ii) элементов матрицы фильтра 0,7, 0,4, 0,9, 0,5 и (iii) сверточная операция 0,5 × 0,7 + 0,2 × 0,4 + 0,2 × 0,7 + 0,7 × 0,5 = 0,92, где 0,92 – первый элемент выходная матрица. Точно так же процесс поэлементного перекрестного умножения и сложения продолжается до тех пор, пока не будут покрыты все значения входной матрицы, и это будет осуществляться путем скольжения фильтра по входной матрице.
Карта характеристик После добавления смещения и функции активации к выходной матрице карта характеристик (A) для данного предложения вычисляется следующим образом [см. (12)]:
$$ A = a_ {i, j} = f \ left ({t_ {i, j} + b} \ right) $$
(12)
, где размерность карты признаков ( A ) для данного предложения = R q × r = R 10 × 4 , где a i, j ϵ R q × r – это элемент ath карты характеристик, b – член смещения, а f – функция активации.
На рис. 2 каждый элемент выходной матрицы затем добавляется к члену смещения после сверточной операции. Например, добавление значения смещения к первому элементу выходной матрицы, равное 0,92 + 1 = 1,92, которое представляет первый элемент карты признаков для данного предложения (рис. 2).
Как показано в алгоритме № 1, параметры, используемые в этом слое, следующие: (i) « фильтры», описывает номер фильтра в сверточном слое; (ii) « размер_ядра», показывает размерность сверточного окна; (iii) «заполнение » содержит одно значение среди трех значений: « допустимо», «одинаково» и « случайное». Если заполнение содержит значение «действительный» , то оно не показывает заполнения, а заполнение значением «тот же» означает, что исходная длина ввода равна длине вывода. Кроме того, когда заполнение содержит значение «случайный» , тогда оно производит расширенную свертку; и (iv) параметр « активация, = и » означает, что активация используется для выявления нелинейности.
Наконец, создается карта характеристик, к которой применяется функция активации relu для устранения нелинейности, и ее математическое выражение выглядит следующим образом: Выход = max (ноль, вход) , где Вход означает элемент карты характеристик.
Например, во входном предложении первый элемент карты признаков равен 1. 92. Если мы применим к нему функцию активации relu, то Выход = max (0, 1,92) , будет Выход = 1,92, поскольку 1,92> 0. Таким образом, вычисляются другие элементы исправленной карты признаков для данного предложения.
Уровень объединения
Уровень объединения используется для минимизации измерения карты объектов путем агрегирования информации. Таким образом, максимальное объединение применяется к каждому предложению в наборе данных.Мы использовали максимальный пул, чтобы получить требуемую характеристику предложения, выбрав максимальное значение. Уравнение (13) представляет формулу для слоя объединения.
$$ g_ {p, h} = max _ {{i, j \ in Z_ {p, h}}} a_ {i, j} $$
(13)
Предположим, Z p, h – небольшая матрица с размером 2 × 2, также g p, h ϵ R 5 × 2 905 905 905 элемент матрицы G и a i, j является элементом матрицы A .Элементы \ (g_ {p, h} \) матрицы G получаются после выбора максимального элемента из матрицы A , которая является исправленной картой признаков для данного предложения, в данной матрице окна, которая равна Z п, h . Следовательно, матрица G отображает объединенную карту признаков данного предложения, которая проиллюстрирована на рис. 6.
Рис. 6Объединенная карта объектов создается путем установки размера окна (2 × 2), размещения его на карте объектов и, наконец, извлечения максимального элемента внутри окна.Поскольку в нашем случае среди выбранного размера окна, то есть max (1,92, 2,3, 2,33, 2,22), самый большой элемент – 2,33, который показывает первый элемент объединенной карты функций, относящийся к данному предложению. Следовательно, такая же процедура будет выполнена для других значений объединенной карты признаков.
Сглаженный слой
Сглаженный слой сверточной нейронной сети преобразует объединенную карту признаков в вектор-столбец, который вводится в нейронную сеть для задачи классификации [39].Вектор-столбец представляет карту характеристик для желаемого предложения. Чтобы объединить строки векторов признаков, объединенная карта признаков выравнивается с помощью функции изменения формы numpy, как показано в уравнении. (14):
$$ Сглаживание \, = \, pooled.reshape \, (4 * 2, \, 1) $$
(14)
Это уравнение берет строку 1, строку 2, строку 3 и так далее, а затем добавляет их все, чтобы получить один вектор-столбец. На рисунке 7 описана функция сглаживания слоя, в котором матрица показывает объединенную карту признаков для предложения, а один вектор-столбец показывает, что операция сглаживания выполняется на объединенной карте признаков предложения.
Рис. 7Выходной слой
На выходном слое функция активации, такая как сигмоид, tanh или softmax, применяется для вычисления вероятности для двух классов, то есть экстремистских и неэкстремистских. Например, желаемый входной текст « Багдади… наша последняя и единственная надежда, я просто люблю тебя», помечается как « экстремистский » при передаче через предложенную модель CNN.
На рис. 8 классификация входного вектора выполняется с помощью функции softmax.{l} w_ {i} x_ {i} + b $$
(15)
, где « w» представляет вектор весовых коэффициентов, « x» представляет входной вектор, а « b» представляет собой член смещения.
Рис.8Применение функции softmax для классификации
Уровень Softmax
Ниже приведены дополнительные функции, используемые в модели LSTM + CNN, как показано в алгоритме 1.
Функция компиляции
Для конфигурации модели используется метод компиляции.Он охватывает различные параметры: (i) потерь, , это целевая функция, (ii) Optimizer, – экземпляр / имя оптимизатора, который используется для компиляции модели, и (iii) Metrics, он содержит метрики оценки.
Сводка модели
Сводка модели будет показана с помощью функции сводки после создания модели.
Подбор модели
Этот раздел псевдокода включает в себя обучение необходимого набора данных, после чего оценка модели выполняется на тестовом наборе данных.Наконец, точность будет выходом модели.
Пример кода реализации приведен в Дополнительном файле 1: Приложение A.
Анализ настроений пользователей, связанных с эмоциональной принадлежностью к экстремистам
В этом модуле проводится классификация настроений пользователей по эмоциям, показывающая их принадлежность к публикациям экстремистов. Каждый вводимый текст помечается категорией эмоций с помощью API анализатора тонов на основе Python [11].Он возвращает набор эмоций: {гнев, печаль, страх, радость, уверенный, аналитический и неуверенный}. В этом модуле вводимый текст анализируется и определяется соответствующий класс эмоций. Например, когда вводимый текст: « Отличные новости, ISIS сражаются с афганскими силами, чтобы захватить Гильменд ..», передается через анализатор эмоций, он возвращает класс эмоций « радость, ». Примерный набор отзывов пользователей и обнаруженный класс эмоций показаны в таблице 5.
Таблица 5 Классификация экстремистских эмоцийSeite nicht gefunden – PEASEC – Wissenschaft und Technik für Frieden und Sicherheit
Текущие
Архив
Архив Monat auswählen август 2021 (3) июль 2021 (3) июнь 2021 (4) май 2021 (6) апрель 2021 (4) марз 2021 (9) февраль 2021 (3) январь 2021 (4) декабрь 2020 (3) ноябрь 2020 ( 6) Октябрь 2020 г. (7) Сентябрь 2020 г. (3) Август 2020 г. (2) Июль 2020 г. (3) Июнь 2020 г. (7) Май 2020 г. (4) Апрель 2020 г. (5) Март 2020 г. (6) Февраль 2020 г. (2) Январь 2020 г. ( 5) Декабрь 2019 г. (5) Ноябрь 2019 г. (5) Октябрь 2019 г. (6) Сентябрь 2019 г. (11) Август 2019 г. (1) Июль 2019 г. (1) Июнь 2019 г. (2) Май 2019 г. (5) Апрель 2019 г. (3) Март 2019 г. ( 3) февраль 2019 г. (1) январь 2019 г. (4) декабрь 2018 г. (5) ноябрь 2018 г. (4) октябрь 2018 г. (7) сентябрь 2018 г. (6) август 2018 г. (5) июль 2018 г. (1) июнь 2018 г. (3) май 2018 г. ( 2) апрель 2018 г. (3) март 2018 г. (2) февраль 2018 г. (2) январь 2018 г. (3) декабрь 2017 г. (3) ноябрь 2017 г. (2) октябрь 2017 г. (5) сентябрь 2017 г. (4) август 2017 г. (1) июль 2017 г. ( 2) июнь 2017 г. (4) май 2017 г. (1) декабрь 2016 г. (1) ноябрь 2016 г. (1) октябрь 2016 г. (1) сентябрь 2016 г. (2) июнь 2016 г. (1) апрель 2016 г. (1) мар z 2016 (1) февраль 2016 г. (1) декабрь 2015 г. (2) ноябрь 2015 г. (1) октябрь 2015 г. (1) сентябрь 2015 г. (2) июнь 2015 г. (1) май 2015 г. (1) март 2015 г. (1) февраль 2015 г. (2) Сентябрь 2014 г. (1) август 2014 г. (1) май 2014 г. (1) декабрь 2013 г. (1) октябрь 2013 г. (2) апрель 2013 г. (1) февраль 2013 г. (1) ноябрь 2012 г. (1) ноябрь 2011 г. (1) июль 2010 г. (1) Май 2010 г. (1) Июнь 2007 г. (1)Nächste 3 Termine
Mensch und Computer ’21: Ингольштадт
5.Сентябрь – 8 сентября
г.Science Peace Security ’21: 2. interdisziplinäre Konferenz für naturwissenschaftlich / technische Friedens- und Sicherheitsforschung, Аахен
8. Сентябрь – 10. Сентябрь
г.Vortrag: Einfluss und Bedeutung sozialer Medien в Krisenzeiten, Notfällen und Falschmeldungen
16.Сентябрь | 13:00 – 14:30
Alle Veranstaltungen anzeigen
Руководство по классификации машинного обучения arXiv
Мы рады видеть внедрение arXiv в быстрорастущую область машинного обучения. Учитывая междисциплинарный характер машинного обучения, нашим модераторам-добровольцам становится сложно не отставать от проверки соответствующих категорий для приложений машинного обучения.
При отправке в arXiv авторы предлагают, какую категорию arXiv они считают наиболее подходящей.Эта классификация определяет, в какой категории будет объявлена статья, и, следовательно, на аудиторию. Наши модераторы проверяют уместность классификации в нашем процессе модерации, а неправильно классифицированные статьи требуют дополнительной работы для исправления нашими модераторами-добровольцами. Это означает, что авторы могут увидеть, что их статья задерживается для объявления и публикации. Чтобы избежать этой задержки, мы рекомендуем вам просматривать категории arXiv при подготовке заявки.
Наше машинное обучение (категория: cs.LG) модераторы наблюдают всплеск 250 представлений (новых статей, перекрестных списков и замен) в день, требующих внимания, и мы ожидаем, что это число будет продолжать расти.
В будущем мы планируем использовать машинное обучение для обработки классификации во время процесса отправки, а не в процессе последующей модерации. Когда авторы отправляют статьи в arXiv, мы будем использовать программное обеспечение классификатора, разработанное Полом Гинспаргом, чтобы предлагать авторам категории. Это часть системы подачи заявок arXiv Next Generation, которую мы планируем пройти бета-тестирование в 2020 году.
А пока мы просим наших авторов просмотреть предметные классы по информатике и подумать о наиболее подходящих перед отправкой. У нас также есть предложения по наиболее распространенным решениям, которые взвешивают авторы.
Мой предмет больше всего подходит для машинного обучения: информатика (cs.LG) или статистика (stat.ML)?
Часто это зависит от области обучения авторов. Статьи по машинному обучению со статистической направленностью (новая статистическая методология / вывод) могут быть более подходящими для статистики.ML. Как правило, в статьях по обучению с подкреплением в качестве основного должен быть указан cs.LG – если только они не подходят больше для math.OC (оптимизация и управление), econ.GN (общая экономика), eess.SY (системы и контроль) или stat.ML ( статистическое обоснование). Статьи, отнесенные к категории stat.ML как основные, автоматически попадают в перекрестный список как cs.LG, но не наоборот.
Я применяю машинное обучение в поле. Какую категорию выбрать?
Если основной домен приложения доступен как другая категория в arXiv и читатели этой категории будут основной аудиторией, эта категория приложения должна быть основной.Примеры включают приложения для компьютерного зрения (cs.CV), обработки естественного языка (cs.CL), распознавания речи (eess.AS), поиска информации (cs.IR; включает классификацию документов, системы рекомендаций, извлечение и распознавание таблиц и темы моделирование), краудсорсинг (cs.HC), обнаружение и моделирование сообществ (cs.SI), образование, здоровье и справедливость (cs.CY), визуализация (cs.GR и, если оценивается с помощью исследований на людях, cs.HC), управление трафиком (cs.SY или cs.AI), графы знаний и онтологии (cs.AI), стенография (cs.MM), новые методы зондирования (cs.ET), количественные финансы (q-fin), количественная биология (q-bio), физика (физика или cond-mat) и астрофизика (astro-ph) .
Что насчет архитектур нейронных сетей?
В статьях, обсуждающих основы архитектур нейронных сетей (функции активации, импульсные нейроны и т. Д.), Следует указать cs.NE в качестве основного, как и статьи, в которых применяются методы оптимизации, вдохновленные биологией, такие как эволюционные методы.
А как насчет машинного обучения, применяемого к таким типам сигналов, как звук и изображения?
Документы, работающие со свойствами определенных типов сигналов (например, звук, ЭЭГ, гиперспектральный, ультразвук), должны учитывать cs.SD (звук, включая музыку), eess.IV (изображения и видео) или eess.SP (обработка сигналов). как первичный. В статьях, изучающих изображения реального мира, следует рассматривать cs.CV как первичный, тогда как в статьях о других сигналах, подобных изображению (фМРТ, рентгеновские лучи, ультразвук, сетчатка глаза и т. Д.)) обычно лучше вписывается в eess.IV. В статьях, использующих методы машинного обучения для решения конкретных задач обработки, следует учитывать тему, в которой обычно публикуются другие подходы для этих задач обработки, например, eess.IV для сжатия или cs.CV для сегментации, независимо от типа обрабатываемых изображений. Статьи, в которых используются методы компьютерного зрения или машинного обучения для атаки на определенные приложения в предметной области (например, обнаружение заболеваний на медицинских изображениях), следует отправлять в темы, связанные с этим приложением, с помощью cs.Резюме как второстепенная тема. Хорошее практическое правило для определения основной темы – спросить, какое отдельное сообщество является наиболее важной группой читателей.
А как насчет компьютеров, помогающих в обучении человека?
cs.CY больше подходит для статей, изучающих человеческое обучение, например, компьютерное обучение. cs.LG подходит в качестве дополнительной категории, если методы машинного обучения применяются к человеческому обучению.
Новости пакетов
Новости пакетовЯ опубликую здесь удобочитаемых материалов .Хотите получать уведомления (без спама, гарантировано )? Затем используйте поле подписки под или подпишитесь через RSS. Список предыдущих сообщений можно найти здесь, а список категорий – здесь. Вы также можете использовать панель поиска, которая появляется перед этим абзацем, если вы ищете более конкретное ключевое слово. У вас есть другие вопросы, связанные с опубликованным здесь контентом? Самый простой / безопасный способ – это , напишите мне по адресу: thierry dot moudiki at pm dot me .
Blogroll | Топ
Список сообщений по дате публикации | Топ
- `перекрестная проверка` и случайный поиск для калибровки опорных векторных машин 6 августа 2021 г.
- параллельная проверка поиска по сетке с использованием перекрестной проверки 31 июля 2021 г.
- “перекрестная проверка” в R-Universe, плюс пример классификации 23 июля 2021 г.
- Документация и исходный код для GPopt, пакета для байесовской оптимизации 02 июля 2021 г.
- Настройка гиперпараметров с помощью GPopt 11 июня 2021 г.
- Инструмент прогнозирования (API) с примерами на curl, R, Python 28 мая 2021 г.
- Байесовская оптимизация с GPopt, часть 2 (сохранение и возобновление) 30 апреля 2021 г.
- Байесовская оптимизация с помощью GPopt 16 апреля 2021 г.
- Совместимость nnetsauce и mlsauce с scikit-learn 26 марта 2021 г.
- Объяснение прогнозов xgboost с кассиром 12 марта 2021 г.
- Бесконечность моделей временных рядов в nnetsauce 6 марта 2021 г.
- Новые функции активации в LSBoost от mlsauce 12 февраля 2021 г. Обзор
- 2020, усиление градиента, обобщенные линейные модели, AdaOpt с nnetsauce и mlsauce 29 декабря 2020 г.
- Архитектура более глубокого обучения в nnetsauce 18 декабря 2020 г.
- Классифицируйте пингвинов с помощью многозадачного классификатора nnetsauce 11 декабря 2020 г.
- Байесовское прогнозирование для одномерных / многомерных временных рядов 4 декабря 2020 г.
- Обобщенные нелинейные модели в nnetsauce 28 ноя.2020
- Повышение нелинейного метода наименьших квадратов со штрафом 21 нояб.2020 г.
- Статистическая объяснимость / машинное обучение с использованием суррогатов регрессии Kernel Ridge 6 нояб.2020 г.
- НОВОСТИ 30 октября 2020 г.
- Взгляд на мое путешествие в докторантуру 23 октября 2020 г.
- Отправка пакета R в CRAN 16 октября 2020 г.
- Моделирование зависимых переменных в ESGtoolkit 9 октября 2020 г.
- Прогнозирование прогрессирования заболеваний легких 2 октября 2020 г.
- Новое нетсусе 25 сен.2020
- Техническая документация 18 сен 2020
- Новая версия nnetsauce и новый веб-сайт Techtonique 11 сен 2020
- Вернусь на следующей неделе, и несколько объявлений 4 сен 2020
- Объяснимый «ИИ» с использованием рандомизированных сетей с градиентным усилением Pt2 (лассо) 31 июля 2020 г.
- LSBoost: объяснимый «ИИ» с использованием рандомизированных сетей с градиентным усилением (с примерами на R и Python) 24 июля 2020 г.
- nnetsauce версии 0.5.0, рандомизированные нейронные сети на GPU 17 июл.2020 г.
- Получение максимальных чаевых в качестве официанта (часть 2) 10 июл.2020 г.
- Новая версия mlsauce, с рандомизированными сетями с градиентным усилением и деревьями решений на корню. 3 июл.2020 г.
- Объявления 26 июня 2020 г.
- Параллельная классификация AdaOpt 19 июня 2020 г.
- Раздел комментариев и другие новости 12 июн.2020 г.
- Получение максимальных чаевых в качестве официанта 5 июн.2020 г.
- Классификация AdaOpt по рукописным цифрам MNIST (без предварительной обработки) 29 мая, 2020
- AdaOpt (вероятностный классификатор, основанный на сочетании многомерной оптимизации и ближайших соседей) для R 22 мая, 2020
- AdaOpt 15 мая 2020
- Пользовательские ошибки для перекрестной проверки с использованием crossval :: crossval_ml 8 мая 2020
- Документация + Pypi для `teller`, инструмент, не зависящий от модели, для объяснимости машинного обучения 1 мая 2020 г.
- Кодирование категориальных переменных на основе переменной ответа и корреляций 24 апреля 2020
- Линейная модель, перекрестная проверка xgboost и randomForest с использованием crossval :: crossval_ml 17 апреля 2020 г.
- Перекрестная проверка поиска по сетке с использованием перекрестной проверки 10 апреля 2020
- Документация для Querier, язык запросов для фреймов данных 3 апреля 2020 г.
- Перекрестная проверка временных рядов с использованием перекрестной проверки 27 марта 2020 г.
- О спецификации, идентификации, степенях свободы и регуляризации модели 20 марта 2020 г.
- Импортировать данные в запросчик (теперь на Pypi), язык запросов для фреймов данных 13 марта 2020 г. Блокноты
- R для nnetsauce 6 марта 2020 г.
- Версия 0.4.0 nnetsauce, с фруктами и классификацией рака груди 28 февраля 2020 г.
- Создайте конкретную ленту в своем блоге Jekyll 21 февраля 2020 г.
- Git / Github за вклад в разработку пакетов 14 февраля 2020 г.
- Формы обратной связи для участия 7 февраля 2020 г.
- netsauce для R 31 янв.2020 г.
- Новая версия nnetsauce (v0.3.1) 24 янв.2020 г.
- ESGtoolkit, инструмент для моделирования Монте-Карло (v0.2.0) 17 янв.2020 г.
- Панель поиска, новый год 2020 10 янв.2020 г.
- 2019 Итоги, nnetsauce, кассир и запрашивающий 20 декабря 2019 г.
- Понимание взаимодействия модели с `кассиром` 13 декабря 2019
- Использование “кассира” в классификаторе 6 декабря 2019 г.
- Сравнение глаголов запрашивающего 29 нояб.2019 г.
- Составление команд запрашивающего для обработки данных 22 ноя.2019
- Сравнение и объяснение прогнозов модели с кассиром 15 ноя.2019
- Тесты на значимость предельных эффектов у кассира 8 нояб.2019 г.
- Представляем кассира 1 нояб.2019 г.
- Знакомство с Querier 25 октября 2019 г.
- Интервалы прогноза для моделей nnetsauce 18 октября 2019 г.
- Использование R в Python для статистического обучения / науки о данных 11 октября 2019 г.
- Калибровка модели с `crossval` 4 октября 2019 г.
- Расфасовка в сетчатом соусе 25 сен.2019
- Обучение Adaboost с nnetsauce 18 сен.2019
- Изменение в презентации блога 4 сен.2019
- netsauce на Pypi 5 июн.2019 г.
- Больше nnetsauce (примеры использования) 9 мая, 2019
- нетсусе 13 марта 2019 г.
- крестовина 13 марта 2019 г.
- тест 10 марта 2019 г.
Категории | Топ
Разное
- Документация и исходный код для GPopt, пакета для байесовской оптимизации
- Настройка гиперпараметров с помощью GPopt
- Инструмент прогнозирования (API) с примерами в curl, R, Python
- Байесовская оптимизация с GPopt, часть 2 (сохранение и возобновление)
- Байесовская оптимизация с помощью GPopt Обзор
- 2020, усиление градиента, обобщенные линейные модели, AdaOpt с nnetsauce и mlsauce
- Статистическая объяснимость / машинное обучение с использованием суррогатов регрессии Kernel Ridge
- НОВОСТИ
- Взгляд на мою кандидатскую диссертацию
- Прогнозирование прогрессирования заболевания легких
- Новое нетсусе
- Техническая документация
- Новая версия nnetsauce и новый веб-сайт Techtonique
- Снова на следующей неделе и несколько анонсов
- Получение максимальных чаевых в качестве официанта (часть 2)
- Новая версия mlsauce с рандомизированными сетями с градиентным усилением и деревьями принятия решений
- Объявления
- Раздел комментариев и другие новости
- Получение максимальных чаевых как официант
- Пользовательские ошибки для перекрестной проверки с использованием crossval :: crossval_ml
- Кодирование категориальных переменных на основе переменной ответа и корреляций
- Линейная модель, перекрестная проверка xgboost и randomForest с использованием crossval :: crossval_ml
- Перекрестная проверка поиска по сетке с использованием перекрестного значения
- Перекрестная проверка временных рядов с использованием перекрестной оценки
- О спецификации, идентификации, степенях свободы и регуляризации модели
- Создайте конкретную ленту в своем блоге Jekyll
- Git / Github за вклад в разработку пакетов
- Формы обратной связи для участия
- Изменение в презентации блога
- тест
Python
- Документация и исходный код для GPopt, пакета для байесовской оптимизации
- Настройка гиперпараметров с помощью GPopt
- Инструмент прогнозирования (API) с примерами в curl, R, Python
- Байесовская оптимизация с GPopt, часть 2 (сохранение и возобновление)
- Байесовская оптимизация с помощью GPopt
- Совместимость nnetsauce и mlsauce с scikit-learn
- Объяснение прогнозов xgboost с кассиром
- Бесконечность моделей временных рядов в nnetsauce Обзор
- 2020, усиление градиента, обобщенные линейные модели, AdaOpt с nnetsauce и mlsauce
- Архитектура более глубокого обучения в nnetsauce
- Обобщенные нелинейные модели в nnetsauce
- Повышение нелинейного метода наименьших квадратов со штрафом
- Техническая документация
- Новая версия nnetsauce и новый веб-сайт Techtonique
- Вернусь на следующей неделе, и несколько анонсов
- Объясняемый «ИИ» с использованием рандомизированных сетей с градиентным усилением Pt2 (лассо)
- LSBoost: объяснимый «ИИ» с использованием рандомизированных сетей с градиентным усилением (с примерами на R и Python)
- nnetsauce версии 0.5.0, рандомизированные нейронные сети на GPU
- Получение максимальных чаевых в качестве официанта (часть 2)
- Параллельная классификация AdaOpt
- Получение максимальных чаевых как официант
- Классификация AdaOpt по рукописным цифрам MNIST (без предварительной обработки)
- AdaOpt
- Документация + Pypi для `teller`, инструмент, не зависящий от модели, для объяснимости машинного обучения
- Кодирование категориальных переменных на основе переменной ответа и корреляций
- Документация для запрашивающего, язык запросов для фреймов данных
- Импортировать данные в запросчик (теперь на Pypi), язык запросов для фреймов данных
- Версия 0.4.0 nnetsauce, с фруктами и классификацией рака груди
- Новая версия nnetsauce (v0.3.1)
- Использование R в Python для статистического обучения / науки о данных
- netsauce на Pypi
R
- `перекрестная проверка` и случайный поиск для калибровки опорных векторных машин
- перекрестная проверка поиска по параллельной сетке с использованием перекрестной проверки
- “перекрестная проверка” в R-вселенной, плюс пример классификации
- Инструмент прогнозирования (API) с примерами в curl, R, Python
- Бесконечность моделей временных рядов в nnetsauce
- Новые функции активации в LSBoost от mlsauce Обзор
- 2020, усиление градиента, обобщенные линейные модели, AdaOpt с nnetsauce и mlsauce
- Классифицируйте пингвинов с помощью многозадачного классификатора nnetsauce
- Байесовское прогнозирование для одномерных / многомерных временных рядов
- Повышение нелинейного метода наименьших квадратов со штрафом
- Статистическая объяснимость / машинное обучение с использованием суррогатов регрессии Kernel Ridge
- Отправка пакета R в CRAN
- Моделирование зависимых переменных в ESGtoolkit
- Прогнозирование прогрессирования заболевания легких
- Объясняемый «ИИ» с использованием рандомизированных сетей с градиентным усилением Pt2 (лассо)
- LSBoost: объяснимый «ИИ» с использованием рандомизированных сетей с градиентным усилением (с примерами на R и Python)
- nnetsauce версии 0.5.0, рандомизированные нейронные сети на GPU
- Получение максимальных чаевых в качестве официанта (часть 2)
- Получение максимальных чаевых как официант
- Классификация AdaOpt по рукописным цифрам MNIST (без предварительной обработки)
- AdaOpt (вероятностный классификатор, основанный на сочетании многовариантной оптимизации и ближайших соседей) для R
- Пользовательские ошибки для перекрестной проверки с использованием crossval :: crossval_ml
- Кодирование категориальных переменных на основе переменной ответа и корреляций
- Линейная модель, перекрестная проверка xgboost и randomForest с использованием crossval :: crossval_ml
- Перекрестная проверка поиска по сетке с использованием перекрестного значения
- Перекрестная проверка временных рядов с использованием перекрестной оценки
- О спецификации, идентификации, степенях свободы и регуляризации модели Блокноты
- R для nnetsauce
- Версия 0.4.0 nnetsauce, с фруктами и классификацией рака груди
- Формы обратной связи для участия
- netsauce за R
- ESGtoolkit, инструмент для моделирования Монте-Карло (v0.2.0)
- Использование R в Python для статистического обучения / науки о данных
- Калибровка модели с крестовиной
- крестовина